Oracle Data Guard: Creating a Logical Standby Database
Benefits of Implementing a Logical Standby Database
A logical standby database provides benefits in disaster recovery, high availability, and data protection that are similar to those of a physical standby database. It also provides the following specialized benefits:
Efficient utilization of system resources
A logical standby database is an open, independent, and active production database. It can include data that is not part of the primary database, and users can perform data manipulation operations on tables in schemas that are not updated from the primary database. It remains open while the tables are updated from the primary database, and those tables are simultaneously available for read access. Because the data can be presented with a different physical layout, additional indexes and materialized views can be created to improve your layout, additional indexes and materialized views can be created to improve your reporting and query requirements and to suit your specific business requirements.
Reduction in primary database workload
The logical standby tables that are updated from the primary database can be used for other tasks (such as reporting, summations, and queries), thereby reducing the primary database workload.
Benefits of Implementing a Logical Standby Database
- Data protection: A logical standby database provides a safeguard against data corruption and user errors. Primary-side physical corruptions do not propagate through the redo data that are transported to the logical standby database. Similarly, user errors that may cause the primary database to be permanently damaged can be resolved before application on the logical standby through delay features.
- Disaster recovery: A logical standby database provides a robust and efficient disaster- recovery solution. Easy-to-manage switchover and failover capabilities enable easy role reversals between primary and logical standby databases, thereby minimizing the down time of the primary database for planned and unplanned outages.
- Database upgrades: Database upgrades: A logical standby database can be used to upgrade Oracle A logical standby database can be used to upgrade Oracle Database software and apply patch sets with almost no down time. The logical standby database can be upgraded to the new release and switched to the primary database role. The original primary database is then converted to a logical standby database and upgraded.
Logical Standby Database: SQL Apply Architecture
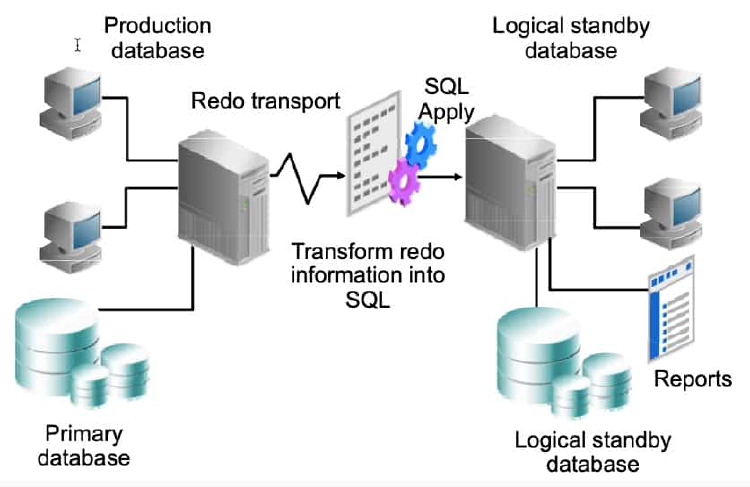
In a logical standby database configuration, Data Guard SQL Apply uses redo information shipped from the primary system. However, instead of using media recovery to apply changes (as in the physical standby database configuration), archived redo log information is transformed into equivalent SQL statements by using LogMiner technology. These SQL statements are then applied to the logical standby database. The logical standby database is open in read/write mode and is available for reporting capabilities.
SQL Apply Process: Architecture
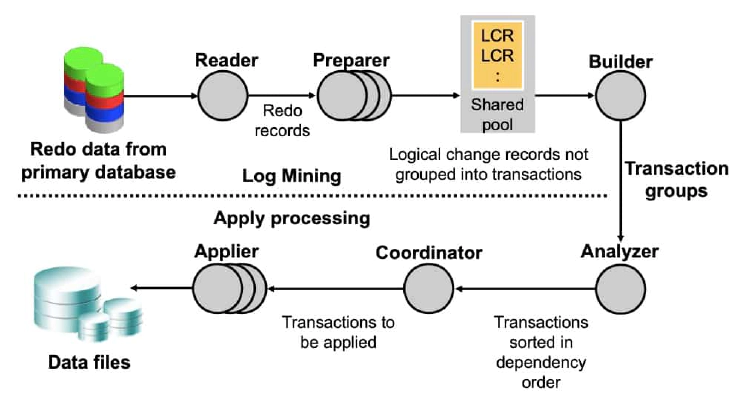
SQL Apply uses a collection of parallel execution servers and background processes that apply changes from the primary database to the logical standby database as follows:
-
The reader process reads redo records from the archived redo log files.
-
The preparer processes convert the block changes into table changes or logical change records (LCRs). At this point, the LCRs do not represent any specific transactions.
-
The builder process assembles completed transactions from the individual LCRs.
-
The analyzer process examines the records, possibly eliminating transactions and identifying dependencies between the different transactions.
-
The coordinator process (LSP):
- Assigns transactions
- Monitors dependencies between transactions and coordinates scheduling
- Authorizes the commitment of changes to the logical standby database
-
The applier process:
-
Applies the LCRs to the database
-
Asks the coordinator process to approve transactions with unresolved dependencies, scheduled appropriately so that the dependencies are resolved.
-
Commits the transactions
Preparing to Create a Logical Standby Database
Perform the following steps on the primary database before creating a logical standby database. The next sections cover the preparation steps in detail.
- Check for unsupported objects.
- Be aware of unsupported DDL commands Be aware of unsupported DDL commands.
- Ensure row uniqueness.
- Verify that the primary database is configured for ARCHIVELOG mode.
When creating a logical standby database, you must take several actions before you begin.
Unsupported Objects
If the primary database contains unsupported tables, log apply services automatically exclude these tables when applying redo data to the logical standby database.
- User tables placed in internal schemas will not be maintained. - Log apply services automatically exclude unsupported objects when applying redo data to the logical standby database. - Unsupported objects:
- Tables and sequences in the SYS schema
- Tables used to support materialized views
- Global temporary tables Global temporary tables
- Tables with unsupported data types (listed in the next slide)
- Log apply services automatically exclude entire tables with unsupported data types when applying redo data to the logical standby database. - Unsupported data types:
- BFILE
- ROWID and UROWID
- Collections (including VARRAYS and nested tables)
- Objects with nested tables and REFS
- The following Spatial types The following Spatial types - MDSYS.SDO_GEORASTER and MDSYS.SDO_TOPO_GEOMETRY.
Ensure that your logical standby database can support the data types of the database objects that are defined in your primary database.
Identifying Internal Schemas
Query DBA_LOGSTDBY_SKIP on the primary database for internal schemas that will be skipped:
SQL> SELECT OWNER FROM DBA_LOGSTDBY_SKIP WHERE STATEMENT_OPT = 'INTERNAL SCHEMA' ORDER BY OWNER;
Owner
-----------------------------------------
ANONYMOUS
APPQOSSYS
AUDSYS
BI
CTXSYS
...
SYSKM
SYSTEM
WMSYS
XDB
XS$NULL
30 rows selected.
Some schemas that ship with the Oracle database (for example, SYSTEM) contain objects that will be implicitly maintained by SQL Apply. However, if you put a user-defined table in SYSTEM, it will not be maintained even if it has columns of supported data types. Query the view DBA_LOGSTANDBY_SKIP to indentify internal schemas as shown in the slide. Tables in these schemas that are created by Oracle will be maintained on a logical standby if the feature implemented in the schema is supported in the context of logical standby. User tables placed in these schemas will not be replicated on a logical standby database and will not show up in the DBA_LOGSTDBY_UNSUPPORTED view.
Checking for Unsupported Tables
Query DBA_LOGSTDBY_UNSUPPORTED on the primary database for unsupported owners and tables:
SQL> SELECT DISTINCT OWNER,TABLE_NAME FROM
DBA_LOGSTDBY_UNSUPPORTED ORDER BY OWNER,TABLE_NAME;
OWNER TABLE_NAME
------------------------------ ------------------------------
IX AQ$_STREAMS_QUEUE_TABLE_G
IX AQ$_STREAMS_QUEUE_TABLE_H
...
OE CATEGORIES_TAB
OE CUSTOMERS OE CUSTOMERS
OE PURCHASEORDER
PM PRINT_MEDIA
SH DIMENSION_EXCEPTIONS
20 rows selected.
You can query DBA_LOGSTDBY_UNSUPPORTED_TABLE to determine which tables in the primary database are not supported by log apply services.
Checking for Tables with Unsupported Data Types
Query DBA_LOGSTDBY_UNSUPPORTED on the primary database for tables with specific unsupported data types:
SQL> SELECT table_name, column_name, data_type FROM
dba_logstdby_unsupported WHERE owner = 'OE';
TABLE_NAME COLUMN_NAME DATA_TYPE
--------------- -------------------- ----------
CUSTOMERS PHONE_NUMBERS VARRAY
PURCHASEORDER SYS_NC_ROWINFO$ OPAQUE
CATEGORIES_TAB CATEGORY_NAME VARCHAR2
CATEGORIES_TAB CATEGORY_DESCRIPTION VARCHAR2
CATEGORIES TAB CATEGORY ID NUMBER
CATEGORIES_TAB PARENT_CATEGORY_ID NUMBER
6 rows selected.
You can query the DBA_LOGSTDBY_UNSUPPORTED data dictionary view to see all tables that contain data types that are not supported by logical standby databases. These tables are not maintained (that is, they do not have DML applied) in the logical standby database. Changes made to unsupported data types, tables, sequences, or views on the primary database are not propagated to the logical standby database, and no error message is returned.
It is a good idea to query this view on the primary database to ensure that those tables that are necessary for critical applications are not in this list before you create the logical standby database. If the primary database includes unsupported tables that are critical, consider using a physical standby database instead.
SQL Commands That Do Not Execute on the Standby Database
- ALTER DATABASE
- ALTER MATERIALIZED VIEW
- ALTER MATERIALIZED VIEW LOG
- ALTER SESSION
- ALTER SYSTEM
- CREATE CONTROL FILE
- CREATE DATABASE
- CREATE DATABASE LINK
- CREATE PFILE FROM SPFILE
- CREATE MATERIALIZED VIEW
- CREATE MATERIALIZED VIEW LOG
- CREATE SCHEMA AUTHORIZATION
- CREATE SPFILE FROM PFILE
- DROP DATABASE LINK
- DROP MATERIALIZED VIEW
- DROP MATERIALIZED VIEW LOG
- EXPLAIN
- LOCK TABLE
- SET CONSTRAINTS SET ROLE
- SET TRANSACTION
Not all data SQL commands that are executed on the primary database are applied to the logical standby database. If you execute any of the commands (shown above) on the primary database, they are not executed on any logical standby database in your configuration. You must execute them on the logical standby database if needed to maintain consistency between the primary database and the logical standby database.
Unsupported PL/SQL-Supplied Packages
Unsupported PL/SQL-supplied packages include:
- DBMS_JAVA
- DBMS_REGISTRY
- DBMS ALERT DBMS_ALERT
- DBMS_SPACE_ADMIN
- DBMS_REFRESH
- DBMS_REDEFINITION
- DBMS AQ
Packages supported only in the context of a rolling upgrade:
SQL> SELECT OWNER, PKG_NAME FROM DBA_LOGSTDBY_PLSQL_SUPPORT
WHERE SUPPORT_LEVEL = 'DBMS_ROLLING';
Oracle PL/SQL-supplied packages that do not modify system metadata or user data leave no footprint in the archived redo log files, and therefore are safe to use on the primary database. Examples of such packages are DBMS_OUTPUT, DBMS_RANDOM, DBMS_PIPE,DBMS_DESCRIBE, DBMS_TRACE, DBMS_METADATA, and DBMS_CRYPTO.
Oracle PL/SQL-supplied packages that do not modify system metadata but may modify user data are supported by SQL Apply, as long as the modified data belongs to the supported data types. Examples of such packages are DBMS_LOB, DBMS_SQL, and DBMS_TRANSACTION.
Oracle Data Guard logical standby supports replication of actions performed through the following packages: DBMS_DDL, DBMS_FGA, SDO_META, DBMS_REDACT, DBMS REDEFINITION DBMS_REDEFINITION, DBMS RLS DBMS_RLS, DBMS SQL TRANSLATOR DBMS_SQL_TRANSLATOR, DBMS XDS DBMS_XDS, DBMS_XMLINDEX, and DBMS_XMLSCHEMA.
Oracle PL/SQL-supplied packages that modify system metadata typically are not supported by SQL Apply, and therefore their effects are not visible on the logical standby database. Examples of such packages are DBMS_JAVA, DBMS_REGISTRY, DBMS_ALERT, DBMS_SPACE_ADMIN, DBMS_REFRESH, and DBMS_AQ.
Ensuring Unique Row Identifiers
Query DBA_LOGSTDBY_NOT_UNIQUE on the primary database to find tables without a unique identifier:
SQL> SELECT * FROM dba_logstdby_not_unique;
OWNER TABLE_NAME BAD_COLUMN
------ -------------------------- ----------
APEX_040200 EMP_HIST Y
SCOTT BONUS N
SCOTT SALGRADE N
SH SUPPLEMENTARY_DEMOGRAPHICS N
SH COSTS N
SH SALES N
- BAD_COLUMN indicates a table column is defined using an unbounded data type such as LONG or BLOB. - Add a primary key or unique index to ensure that SQL Apply can efficiently apply data updates.
Because the row IDs on a logical standby database might not be the same as the row IDs on the primary database, a different mechanism must be used to match the updated row on the primary database to its corresponding row on the logical standby database. Primary keys and non-null unique indexes can be used to match the corresponding rows. It is recommended that you add a primary key or a unique index to tables on the primary database (whenever appropriate and possible) to ensure that SQL Apply can efficiently apply data updates to the logical standby database.
You can query the DBA_LOGSTDBY_NOT_UNIQUE view to identify tables in the primary database that do not have a primary key or unique index with NOT NULL columns. Issue the following query to display a list of tables that following query to display a list of tables that SQL Apply might not be able to uniquely identify:
SQL> SELECT OWNER, TABLE_NAME,BAD_COLUMN
2 FROM DBA_LOGSTDBY_NOT_UNIQUE
3 WHERE TABLE_NAME NOT IN
4 (SELECT TABLE_NAME FROM DBA_LOGSTDBY_UNSUPPORTED);
The key column in this view is BAD_COLUMN. If the view returns a row for a given table, you may want to consider adding a primary or unique key constraint on the table.
A value of Y indicates that the table does not have a primary or unique constraint and that the column is defined using an unbounded data type (such as CLOB). If two rows in the table match except for values in their LOB columns, the table cannot be maintained properly and SQL Apply stops.
A value of N indicates that the table does not have a primary or unique constraint, but that it contains enough column information to maintain the table in the logical standby database. However, the redo transport services and log apply services run more efficiently if you add a primary key. You should consider adding a disabled RELY constraint to these tables (as described in the next slide) described in the next section).
Adding a Disabled Primary Key RELY Constraint
You can add a disabled RELY constraint to uniquely identify rows:
SQL> ALTER TABLE hr.employees
2 ADD PRIMARY KEY ( l id l t ) 2 ADD PRIMARY KEY (employee_id, last_name)
3 RELY DISABLE;
If your application ensures that the rows in a table are unique, you can create a disabled primary key RELY constraint on the table without incurring the overhead of maintaining a primary key on the primary database.
The RELY constraint tells the system to log the named columns (in this example, EMPLOYEE_ID and LAST_NAME) to identify rows in this table. Be careful to select columns for the disabled RELY constraint that uniquely identify the row. If the columns selected for the RELY constraint do not uniquely identify the row, SQL Apply does not apply redo information to the logical standby database.
To improve the performance of SQL Apply, add a unique constraint/index to the columns to identify the row on the logical standby database. Failure to do so results in full table scans during UPDATE or DELETE statements carried out on the table by SQL Apply.
Creating a Logical Standby Database by Using SQL Commands
To create a logical standby database by using SQL commands:
- Create a physical standby database.
- Stop Redo Apply on the physical standby database.
- Prepare the primary database to support a logical standby Prepare the primary database to support a logical standby database.
- Build a LogMiner dictionary in the redo data.
- Transition to a logical standby database.
- Open the logical standby database.
- Verify that the logical standby database is performing properly.
Step 1: Create a Physical Standby Database
You create a logical standby database by first creating a physical standby database. Then you convert the physical standby database into a logical standby database.
To create the physical standby database:
a. Create a physical standby database. b. Ensure that the physical standby database is current with the primary database by allowing recovery to continue until the physical standby database is consistent with the primary database, including all database structural changes (such as adding or dropping data files).
Step 2: Stop Redo Apply on the Physical Standby Database
Before converting the physical standby database to a logical standby database, stop Redo Apply. Stopping Redo Apply is required to avoid applying changes past the redo that contains the LogMiner dictionary.
To stop Redo Apply, issue one of the following commands:
1. If the configuration is not managed by the broker:
DGMGRL> EDIT DATABASE '[db_name]' set state='apply-off';
Step 3: Prepare the Primary Database to Support Role Transitions
Set the LOG_ARCHIVE_DEST_n initialization parameter for transitioning to a logical standby role.
LOG_ARCHIVE_DEST_1='LOCATION /arch1/boston/ 'LOCATION=/arch1/boston/ VALID_FOR=(ONLINE_LOGFILES,ALL_ROLES)DB_UNIQUE_NAME=boston'
LOG_ARCHIVE_DEST_3='LOCATION=/arch2/boston/ VALID_FOR=(STANDBY_LOGFILES,STANDBY_ROLE) DB_UNIQUE_NAME=boston'
LOG_ARCHIVE_DEST_STATE_3=ENABLE
Note: This step is necessary only if you plan to perform switchovers.
If you plan to transition the primary database to the logical standby role, you must also modify the parameters so that no parameters need to change after a role transition:
- Change the VALID FOR attribute in the original LOG ARCHIVE DEST 1 destination to archive redo data only from the online redo log and not from the standby redo log.
- Include the LOG_ARCHIVE_DEST_3 destination on the primary database. This parameter only takes effect when the primary database is transitioned to the logical standby role.
When the boston database is running in the primary role, LOG_ARCHIVE_DEST_1 directs archiving of redo data generated by the primary database from the local online redo log files to the local archived redo log files in /arch1/boston and LOG_ARCHIVE_DEST_3 is not used.
When the boston database is running in the logical standby database role, LOG_ARCHIVE_DEST_1 directs archiving of redo data generated by the logical standby database from the local online redo log files to the local archived redo log files in/arch1/boston/.
LOG ARCHIVE DEST 3 LOG_ARCHIVE_DEST_3 directs archiving of redo data from the standby redo log files to the to the local archived redo log files in /arch2/boston/.
Step 4: Build a LogMiner Dictionary in the Redo Data
SQL Apply requires a LogMiner dictionary in the redo data so that it can properly interpret changes in the redo. When you execute the DBMS_LOGSTDBY.BUILD procedure, the LogMiner dictionary is built and supplemental logging is automatically enabled for logging primary key and unique key columns. Supplemental logging ensures that each update contains enough information to logically identify the affected row.
Execute the procedure on the primary database:
SQL> EXECUTE DBMS_LOGSTDBY.BUILD;
Step 5: Transition to a Logical Standby Database
To prepare the physical standby database to transition to a logical standby database:
a. Issue the ALTER DATABASE RECOVER TO LOGICAL STANDBY db_name command to continue applying redo data to the physical standby database until it is ready to convert to a logical standby database. Specify a database name (db_name) to identify the new logical standby database.
SQL> ALTER DATABASE RECOVER TO LOGICAL STANDBY db_name;
The redo log files contain the information needed to convert your physical standby database to a logical standby database. The statement applies redo data until the LogMiner dictionary is found in the redo log files.
b. Shut down the logical standby database instance and restart it in MOUNT mode.
c. Modify the LOG ARCHIVE DEST_n parameters to specify separate local destinations for: - Archived redo log files that store redo data generated by the logical standby database. - Archived redo log files that store redo data received from the primary database.
Step 6: Open the Logical Standby Database
To open the logical standby database and start SQL Apply: a. On the logical standby database, issue the ALTER DATABASE OPEN RESETLOGS command to open the database.
SQL> ALTER DATABASE OPEN RESETLOGS;
b. On the logical standby database, issue the following command to start SQL Apply:
SQL> ALTER DATABASE START LOGICAL STANDBY APPLY IMMEDIATE;
Step 7: Verify That the Logical Standby Database Is Performing Properly
After creating your logical standby database and setting up redo transport services and log apply services, you should verify that redo data is being transmitted from the primary database and applied to the standby database.
To verify that the logical standby database is functioning properly:
1. Connect to the logical standby database and query the DBA_LOGSTDBY_LOG view to verify that the archived redo log files were registered on the logical standby system:
SQL> SELECT SEQUENCE#, FIRST_TIME, NEXT_TIME, DICT_BEGIN,DICT_END FROM DBA_LOGSTDBY_LOG ORDER BY SEQUENCE#;
2. Connect to the primary database and issue the following command to begin sending redo data to the standby database:
SQL> ALTER SYSTEM ARCHIVE LOG CURRENT;
3. Connect to the logical standby database and requery the DBA_LOGSTDBY_LOG view as shown in step a. This enables you to verify that the new archived redo log files were registered.
4. On the logical standby database, query the V$LOGSTDBY_STATS view to verify that redo data is being applied correctly:
SQL> SELECT NAME, VALUE FROM V$LOGSTDBY STATS WHERE NAME ='coordinator state';
A value of INITIALIZING in the VALUE column indicates that log apply services are preparing to begin SQL Apply, but that data from the archived redo log files is not being applied to the logical standby database.
5. Query the V$LOGSTDBY_PROCESS view to see information about the current state of the SQL Apply processes.
SQL> SELECT sid, serial#, spid, type, high_scn
FROM v$logstdby_process;
6. Query the V$LOGSTDBY_PROGRESS view on the logical standby database to check the overall progress of SQL Apply:
SQL> SELECT APPLIED_SCN, LATEST_SCN FROM V$LOGSTDBY_PROGRESS;
Securing Your Logical Standby Database
The database guard controls user access to tables in a logical standby database. Use the ALTER DATABASE GUARD command to configure the database guard.
By default, it is not possible for a nonprivileged user to modify data on a Data Guard SQL Apply database, because the database guard is automatically set to ALL. With this level of security, only the SYS user can modify data.
When you set the security level to STANDBY, users are able to modify data that is not maintained by the logical apply engine. A security level of NONE permits any users to access the standby database if they have the appropriate privileges.
When creating a logical standby database manually with SQL commands, you must issue the ALTER DATABASE GUARD ALL command before opening the database. Failure to do so allows jobs that are submitted through DBMS_JOB.SUBMIT to be scheduled and to potentially modify tables in the logical standby database.
Automatic Deletion of Redo Log Files by SQL Apply
Archived redo logs on the logical standby database are automatically deleted by SQL Apply after they are applied. This feature reduces the amount of space consumed on the logical standby database and eliminates the manual step of deleting the archived redo log files.
You can enable and disable the auto-delete feature for archived redo logs by using the DBMS_LOGSTDBY.APPLY_SET procedure. By default, the auto-delete feature is enabled.
Managing Remote Archived Log File Retention
The LOG_AUTO_DEL_RETENTION_TARGET parameter:
- Is used to specify the number of minutes that SQL Apply keeps a remote archived log after completely applying its contents
- Is applicable only if LOG_AUTO_DELETE is set to TRUE and the flash recovery area is not being used to store remote archived logs
- Has a default value of 1,440 minutes
SQL> execute DBMS_LOGSTDBY.APPLY_SET ('LOG_AUTO_DEL_RETENTION_TARGET','2880');
By default, SQL Apply deletes an archived redo log file after applying the contents. This behavior is controlled by the LOG_AUTO_DELETE parameter. During a flashback operation or point-in-time recovery of the logical standby database, SQL Apply must stop and re-fetch all remote archived redo log files.
In Oracle Database 12c, you use the LOG_AUTO_DEL_RETENTION_TARGET parameter to specify a retention period for remote archived redo log files. You can modify LOG_AUTO_DEL_RETENTION_TARGET by using the DBMS_LOGSTDBY.APPLY_SET and DBMS_LOGSTDBY.APPLY_UNSET procedures.
Creating SQL Apply Filtering Rules
Procedures exist to create SQL Apply filtering rules.
- To skip SQL statements:
SQL> EXECUTE DBMS_LOGSTDBY.SKIP(STMT => 'DML', schema_name => 'HR', object_name => '%');
- To skip errors and continue applying changes:
SQL> EXECUTE DBMS_LOGSTDBY.SKIP_ERROR('GRANT');
- To skip applying transactions:
SQL> EXECUTE DBMS LOGSTDBY SKIP TRANSACTION (XIDUSN => 1, XIDSLT => 13, XIDSQN => 1726);
- To skip all SQL statements for a container:
SQL> EXECUTE DBMS_LOGSTDBY.SKIP(stmt => 'CONTAINER', object_name => 'DEV1');
You can use SQL Apply filters to control what to apply and what not to apply. To define a SQL Apply filter, use the DBMS_LOGSTDBY package with the SKIP, SKIP_ERROR, and SKIP_TRANSACTION procedures. The first example in the slide uses the SKIP procedure to ignore all DML changes made to the HR schema. The second example in the slide uses the SKIP_ERROR procedure to ignore any error raised from any GRANT DDL command and continue applying changes instead of stopping SQL Apply. The third example in the slide uses the SKIP_TRANSACTION procedure and skips a DDL transaction with XIDUSN=1, XIDSLT=13, and XIDSQN=1726. The following describes the fields used:
- XIDUSN NUMBER: Transaction ID undo segment number of the transaction being skipped.
- XIDSLT NUMBER: Transaction ID slot number of the transaction being skipped.
- XIDSQN NUMBER: Transaction ID sequence number of the transaction being skipped.
Deleting SQL Apply Filtering Rules
Procedures exist to delete SQL Apply filtering rules.
- To delete SQL statement rules:
SQL> EXECUTE DBMS_LOGSTDBY.UNSKIP(STMT => 'DML', schema name => 'HR', object name => '%');
- To delete error apply filter rules:
SQL> EXECUTE DBMS_LOGSTDBY.UNSKIP_ERROR('GRANT');
- To delete transaction filter rules:
SQL> EXECUTE DBMS_LOGSTDBY.UNSKIP_TRANSACTION (XIDUSN => 1, XIDSLT => 13, XIDSQN => 1726);
To delete a SQL Apply filter, use the DBMS_LOGSTANDBY package with the UNSKIP, UNSKIP_ERROR, and UNSKIP_TRANSCATION procedures. The syntax to delete a SQL Apply filter is almost identical to the syntax to create a SQL Apply filter.
Viewing SQL Apply Filtering Settings
You can query the DBA_LOGSTDBY_SKIP view on the logical standby database to determine the SQL Apply filtering settings.
SQL> SELECT error, statement_opt, name
2 FROM dba logstdby skip 2 FROM dba_logstdby_skip
3 WHERE owner='HR';
ERROR STATEMENT_OPT NAME
---------- ----------------- ----------
N DML JOBS
The view contains the following columns:
- ERROR: Indicates whether the statement should be skipped or should return an error for the statement
- STATEMENT_OPT: Specifies the type of statement that should be skipped (It must be one of the SYSTEM_AUDIT statement options.)
- OWNER: Name of the schema under which the skip option is used
- NAME: Name of the table that is being skipped
- USE_LIKE: Indicates whether the statement uses a SQL wildcard search when matching names
- ESC: Escape character to be used when performing wildcard matches
- PROC: Name of a stored procedure that is executed when processing the skip option
You can query DBA_LOGSTDBY_SKIP_TRANSACTION to view settings for transactions to be skipped.
Using DBMS_SCHEDULER to Create Jobs on a Logical Standby Database
Use the DBMS_SCHEDULER package to create Scheduler jobs so that they are executed when intended. Scheduler jobs can be created on a standby database.
When a Scheduler job is created, it defaults to the local role. If the job is created on the standby database, it defaults to the role of a logical standby. The Scheduler executes jobs that are specific to the current database role. Following a role transition (switchover or failover), the Scheduler automatically switches to executing jobs that are specific to a new role.
Scheduler jobs are replicated to the standby, but they do not run by default. However, existing jobs can be activated under the new role by using the DBMS_SCHEDULER.SET_ATTRIBUTE procedure. If you want a job to run for all database roles on a particular host, you must create two copies of the job on that host: one with a database_role of PRIMARY and the other with a database_role of LOGICAL STANDBY. Query the DBA_SCHEDULER_JOB_ROLES view to determine which jobs are specific to which role.