Beginners Guide to MySQL Replication
MySQL Replication
Replication in MySQL copies changes from one server―the master―to one or more slaves. The master writes changes to the binary log, and slaves request the master’s binary log and apply its contents. The format of the log file affects how slaves apply changes. MySQL supports statement-based, row-based, and mixed-format logging.
Number of Slaves
There is no limit on how many slaves a single master can have. However, each additional slave uses a small amount of resources on the master, so you should carefully consider the benefit of each slave in production setups. The optimal number of slaves for a master in a given environment depends on a number of factors: size of schema, number of writes, relative performance of master and slaves, and factors such as CPU and memory availability. A general guideline is to limit the number of slaves per master to no more than 30.
Network Outages
Replication in MySQL survives a network outage. Each slave keeps track of how much of the log it has processed, and resumes processing automatically when network connectivity is restored. This behavior is automatic and requires no special configuration.
Replication Masters and Slaves
The master/slave relationship is one-to-many:
- Each slave reads logs from one master.
- A master can ship logs to many slaves.
- A slave can act as the master to another slave.
Relay Slave
A slave can act as a master to another slave. Changes that occur at the top-most master are requested and applied by its immediate slaves, which relay the changes down to their slaves, and so on until replication reaches the end of the chain. This enables updates to propagate through multiple levels of replication, allowing for topologies that are more complex. Each additional level adds more propagation delays into the system, so a shallower setup suffers from less replication lag than a deeper one.
Each slave server can have only one master server; one slave cannot replicate from multiple master servers. A slave that acts as a master to other servers is often called a relay slave.
Replicating with the BLACKHOLE Storage Engine
The BLACKHOLE storage engine silently discards all data changes with no warnings. The binary log continues to record those changes successfully. Use BLACKHOLE for specific tables on a relay slave when it replicates all changes to further slaves, but does not itself need to store data in those tables. For example, if you have a relay slave that is used solely for executing frequent long-running business intelligence reports on a small number of tables, you can configure all other replicated tables to use BLACKHOLE so that the server does not store data it does not need, while it replicates all changes to its slaves.
Complex Topologies
More complex topologies are possible:
1. A bi-directional topology has two master servers, each a slave of the other. 2. A circular topology has any number of servers. – Each is both a master and a slave of another master. – Changes on any master replicate to all masters. 3. Not every slave must be a master.
Conflict Resolution
In a typical configuration, clients write changes only to the master but read changes from any server. In an environment where servers allow concurrent updates on similar data, the eventual state of the data on multiple servers might become inconsistent. It is the responsibility of the application to prevent or manage conflicting operations. MySQL replication does not perform conflict resolution.
Conflicts can occur in any topology that includes more than one master. Conflicts are particularly prevalent in circular topologies.
For example, consider an e-commerce company that implements replication using a circular topology, in which two of the servers deal with applications in the “Luxury Brands” and “Special Events” teams, respectively. Assume that the applications do not manage conflicting operations, and the following events occur:
- The “Luxury Brands” team increases the price of luxury products by 20%.
- The “Special Events” team reduces the prices of all products over $500 by $50 because of an upcoming special holiday.
- One product costing $520 falls into both categories and has its value updated by both of the preceding operations.
The eventual price of the product on each server depends on the order in which each server performs the operations. If both operations occur almost at the same time, the following operations occur:
- The server in the “Luxury Brands” team increases the product’s price by 20%, from $520 to $624
- The server in the “Special Events” team reduces the product’s price by $50, from $520 to $470
- The changes each replicate to the other server, resulting in the “Luxury Brands” server assuming a final value for that product of $574, and the “Special Events” server assuming a final value of $564.
- Other servers in the replication environment assume final values depending on the order in which they applied the operations.
Similarly, conflicts occur if the “Luxury Brands” team adds a new product that has not replicated fully by the time the “Special Events” team makes its changes, or if two teams add a product with the same primary key on different servers. While row-based replication solves some conflicts, many conflicts can be prevented only at the application level.
Replication Use Cases
Common Use Cases
- Horizontal scale-out: The most popular reason to implement replication is to spread the querying workload across one or more slave servers to improve the performance of read operations throughout the application, and write operations on the master server by reducing its read workload.
- Business intelligence and analytics: Business intelligence reports and analytical processing can be resource intensive and can take considerable time to execute. In a replicated environment, you can run such queries on a slave so that the master can continue to service the production workload without being affected by long-running and I/O intensive reports.
- Geographic data distribution: Companies with a distributed geographic presence can benefit from replication by having servers in each region that process local data and replicate that data across the organization. This provides the performance and administrative benefits of geographic proximity to customers and the workforce, while also enabling corporate awareness of data throughout the company.
Replication for High Availability
Replication allows you to fail over to the slave server if the master goes offline due to hardware or software failure, or to perform scheduled maintenance.
Replication allows various high-availability use cases.
- Controlled switchover: Use a replica to act in place of a production server during hardware or system upgrades.
- Server Redundancy: Perform a failover to a replica server in case of a system failure.
- Online schema changes: Perform a rolling upgrade in an environment with several servers to avoid an overall system outage.
- Software upgrades: Replicate across different versions of MySQL during an environment upgrade. Slaves must run a later version than the master. Queries issued during the upgrade must be supported by all versions used during the upgrade process.
Configuring Replication
Every server in a replication topology must have a unique server-id, an unsigned 32-bit integer with a value from 0 (the default) to 4,294,967,295. A server with a server-id of 0, whether slave or master, refuses to replicate with other servers.
Master Configuration
Every master must have an assigned IP address and TCP port, because replication cannot use UNIX socket files. Each master must also enable binary logging, because during replication, each master sends its log contents to each slave.
Each slave must log on to a master to replicate from it. If you are creating a new user on the master for that purpose, that new user must have the REPLICATION SLAVE privilege:
GRANT REPLICATION SLAVE ON *.* TO [user]@[slave-hostname];
If you are creating a replication topology using a master that already contains a populated database, you must create a copy of that database as a starting point for the slave (for example, by performing a backup of the master and restoring that backup to the slave).
If you are using Global Transaction Identifiers, you do not need to record log coordinates.
Slave Configuration
Each slave connects to only one master. To tell the slave about the master, use the CHANGE MASTER TO… statement.
CHANGE MASTER TO
Issue the CHANGE MASTER TO… statement on the slave to configure replication master connection details:
mysql> CHANGE MASTER TO
-> MASTER_HOST = 'host_name',
-> MASTER_PORT = port_num,
-> MASTER_USER = 'user_name',
-> MASTER_PASSWORD = 'password',
-> MASTER_LOG_FILE = 'master_log_name',
-> MASTER_LOG_POS = master_log_pos;
Subsequent invocations of CHANGE MASTER TO retain the value of each unspecified option. Changing the master’s host or port also resets the log coordinates. The following statement changes the password, but retains all other settings:
mysql> CHANGE MASTER TO MASTER_PASSWORD='newpass';
The MASTER_HOST and MASTER_PORT values specify the hostname and TCP port number of the master. The MASTER_USER and MASTER_PASSWORD values specify the account details of an account on the master with the REPLICATION SLAVE privilege. To improve security, you can also use MASTER_SSL and related options on SSL-enabled servers to encrypt network traffic between slave and master during replication.
The MASTER_LOG_FILE and MASTER_LOG_POS values contain the log coordinates of the binary log position from which the slave starts replicating. You can get the file and position from the master by executing the SHOW MASTER STATUS statement:
mysql> SHOW MASTER STATUS;
+------------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+------------------+----------+--------------+------------------+-------------------+
| mysql-bin.000014 | 51467 | | | |
+------------------+----------+--------------+------------------+-------------------+
1 row in set (0.00 sec)
If you use mysqldump to perform a backup of the master’s databases as a starting point for the slave, you can use the –master-data option to include log coordinates in the backup:
mysqldump -uroot -p --master-data -B world_innodb > backup.sql
Specify MASTER_AUTO_POSITION=1 instead of log coordinates if you are using GTIDs.
Failover with Log Coordinates
To fail over after a master becomes unavailable, stop all slaves and select a slave as the new master by issuing a CHANGE MASTER TO statement (with the log coordinates of that new master) on the remaining slaves. If the slaves are not all up-to-date when you failover, you risk having an inconsistent replication topology:
- If the new master is behind a particular slave (that is, if the slave has already applied the events at the end of the new master’s log), the slave repeats those events.
- If the new master is ahead of a particular slave (that is, if the new master’s binary log contains events that the slave has not yet applied), the slave skips those events.
To avoid such inconsistencies, you must select an up-to-date slave as new master, and then find the log coordinates on the new master that match the most recent event on each slave. If some slaves are more behind than others, the log coordinates that you provide in the CHANGE MASTER TO… statement differ from one slave to the next, so you cannot simply issue a SHOW MASTER STATUS on the new master. Instead, you must examine the binary logs to find the correct coordinates.
In circular topologies with multiple masters accepting client updates, finding an up-to-date slave and identifying correct log coordinates can be very difficult, because each slave applies operations in a different order to other slaves. To avoid this difficulty, use Global Transaction Identifiers (GTIDs). The MySQL Utilities also include tools to facilitate failover with GTIDs.
Global Transaction Identifiers (GTIDs)
Global Transaction Identifiers (GTIDs) uniquely identify each transaction in a replicated network. Each GTID is of the form:
0ed18583-47fd-11e2-92f3-0019b944b7f7:338
A GTID set contains a range of GTIDs:
0ed18583-47fd-11e2-92f3-0019b944b7f7:1-338
Enable GTID mode with the following options:
- gtid-mode=ON: Logs a unique GTID along with each transaction.
- enforce-gtid-consistency: Disallows events that cannot be logged in a transactionally safe way.
- log-slave-updates: Records replicated events to the slave’s binary log.
The source UUID (universally unique identifier) is the UUID of the originating server for each transaction. Each server’s UUID is stored in the auto.cnf file in the data directory. If that file does not exist, MySQL creates the file and generates a new UUID, placing it in the new file. Query a server’s UUID with the server_uuid variable:
mysql> SELECT @@server_uuid\G
*************************** 1. row ***************************
@@server_uuid: 0ed18583-47fd-11e2-92f3-0019b944b7f7
1 row in set (0.00 sec)
When a client executes a transaction on a master, MySQL creates a new GTID and logs the transaction with its unique GTID. When a slave reads that transaction from the master and applies it, the transaction retains its original GTID. That is, the server UUID of a transaction replicated to a slave is that of the master, not the slave. Subsequent slaves in a replication chain each record the transaction along with its original GTID. As a result, every slave in a replication topology can identify the master on which a transaction first executed.
When each server logs a transaction, it also records that transaction’s ID in a GTID set within the gtid_executed variable. In a global context, this variable contains all GTID sets (representing all transactions from this and other upstream master servers) logged to the server’s binary log.
mysql> SELECT @@global.gtid_executed\G
*************************** 1. row ***************************
@@global.gtid_executed: bacc034d-4785-11e2-8fe9-0019b944b7f7:1-34,
c237b5cd-4785-11e2-8fe9-0019b944b7f7:1-9,
c9cec614-4785-11e2-8fea-0019b944b7f7:1-839
1 row in set (0.00 sec)
The gtid_purged variable contains GTID sets that have been purged from the binary log. Both gtid_purged and the global gtid_executed are reset to an empty string when you execute RESET MASTER on the server.
Replication with GTIDs
Use CHANGE MASTER TO… to enable GTID replication. Tell the slave that transactions are identified by GTIDs:
CHANGE MASTER TO MASTER_AUTO_POSITION=1;
You do not need to provide log coordinates such as - MASTER_LOG_FILE and MASTER_LOG_POS and you cannot provide MASTER_AUTO_POSITION and log coordinates in the same CHANGE MASTER TO… statement.
When you enable GTID-based replication, you do not need to specify the log coordinates of the master, because the slave sends the value of @@global.gtid_executed to the master. Therefore, the master knows which transactions the slave has executed, and sends only those transactions that the slave has not already executed.
Failover with GTIDs
When you use GTIDs, failover in a circular topology is trivial:
1. On the slave of the failed master, bypass it by issuing a single CHANGE MASTER TO statement. 2. Each server ignores or applies transactions replicated from other servers in the topology, depending on whether the transaction’s GTID has already been seen or not.
Failover in a non-circular topology is similarly easy. Temporarily configure the new master as a slave of an up-todate slave until it has caught up. Although GTIDs prevent the duplication of events that originated on a single server, they do not prevent conflicting operations that originated on different servers. When reconnecting applications to your servers following a failover, you must be careful not to introduce such conflicts.
Replication Filtering Rules
Filters are server options that apply to a master or slave. The master applies binlog-* filters when writing the binary log. The slave applies replicate-* filters when reading the relay log.
Use filtering rules when different slaves in an environment serve different purposes. For example, a server dedicated to displaying web content does not need to replicate restocking information or payroll records from the master, while a server dedicated to generating management reports on sales volume does not need to store web content or marketing copy.
Be careful when using multiple filters. It is very easy to make mistakes, due to the complex order in which filters are applied. Because filters control what data is replicated, such mistakes are difficult to recover from. For this reason, do not mix different types of filters. For example, if you use replicate-wild-*, do not use any non-wild replicate-* filters. To suppress replication of all temporary tables, set binlog_format=ROW. To suppress replication of a specific temporary table, use replicate-ignore-table.
Filtering rules have complex precedence rules that apply in order:
- Database filters apply before table filters.
- Table wildcard filters *-wild-* apply after those that do not use wildcards.
- The *-do-* filters apply before the respective *-ignore-* filters.
Choose which events to replicate, based on: Database: – replicate-do-db, binlog-do-db – replicate-ignore-db, binlog-ignore-db Table: – replicate-do-table, replicate-wild-do-table – replicate-ignore-table, replicate-wild-ignore-table
MySQL Utilities
MySQL Utilities are command-line tools that provide a number of useful features. They are:
- Distributed with MySQL Workbench
- Used for maintenance and administration of MySQL servers
- Written in Python, and easily extensible by Python programmers using a supplied library
- Useful for configuring replication topologies and performing failover
MySQL Utilities for Replication
Several utilities are particularly useful for replication:
-
mysqldbcopy: Copies a database from a source server to a destination server along with replication configuration
-
mysqldbcompare: Compares two databases to find differences and create a script to synchronize them
-
mysqlrpladmin: Administers a replication topology
- Failover to the best slave after a master failure
- Switchover to promote a specified slave
- Start, reset, or stop all slaves
-
mysqlfailover: Monitors a master continuously, and executes failover to the best slave available
The mysqldbcopy utility accepts the option –rpl that runs a CHANGE MASTER TO statement on the destination server. It accepts the following values:
- master: The destination server becomes a slave of the source.
- slave: The source is already a slave of another master. The destination server copies that master information from the source and becomes a slave of the same master.
The mysqlfailover utility checks the master status periodically with a ping operation. Both the period interval and ping operation are configurable. It uses GTIDs to ensure that a new master is fully up-to-date when it becomes the master, doing so by choosing a new master from a list of candidates (optionally from all slaves if no candidate in the list is viable), configuring it as a slave of all other slaves to collect all outstanding transactions, before finally making it the new master. The failover command of mysqlrpladmin performs a similar temporary reconfiguration when selecting a new master. You can also perform health monitoring without performing automatic reconfiguration if a master fails.
MySQL Utilities for Replication
-
mysqlrplcheck: Checks the prerequisites for replication between a master and a slave, including:
- Binary logging
- Replication user with appropriate privileges
- server_id conflicts
- Various settings that can cause replication conflicts
-
mysqlreplicate: Starts replication between two servers, reporting warnings for mismatches.
-
mysqlrplshow: Displays a replication topology between a master and slave or recursively for the whole topology.
The mysqlrplshow utility displays a replication topology such as the following:
# Replication Topology Graph
localhost:3311 (MASTER)
|
+--- localhost:3312 - (SLAVE + MASTER)
|
+--- localhost:3313 - (SLAVE + MASTER)
|
+--- localhost:3311 <--> (SLAVE)
In the preceding example, the server at port 3311 appears twice: once as master and once as slave. The symbol indicates circularity within the topology.
Asynchronous Replication
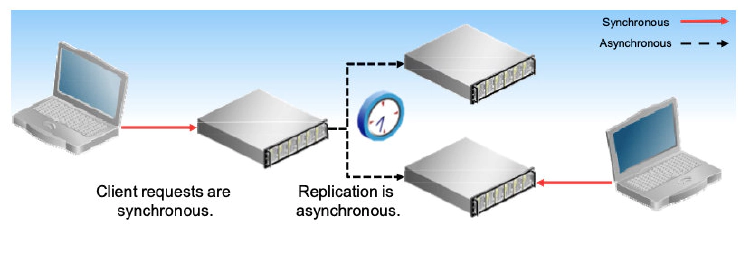
During MySQL replication in its default configuration, the master server accepts change events from clients, committing those events and writing them to the binary log. In a separate thread, the master streams the binary log to connected slaves. Because the master commits changes without waiting for a response from any slave, this is called asynchronous replication.
Most importantly, this means that slaves have not yet applied transactions at the time the master reports success to the application. Usually, this is not a problem. However, if the master crashes with data loss after committing a transaction but before the transaction replicates to any slave, the transaction is lost even though the application has reported success to the user.
If the master waited for all slaves to apply its changes before committing the transaction, replication would then be called synchronous. Although MySQL replication is not synchronous, MySQL Cluster uses synchronous replication internally to ensure data consistency throughout the cluster, and MySQL client requests are synchronous because the client waits for a server response after issuing a query to the server.
Semisynchronous Replication
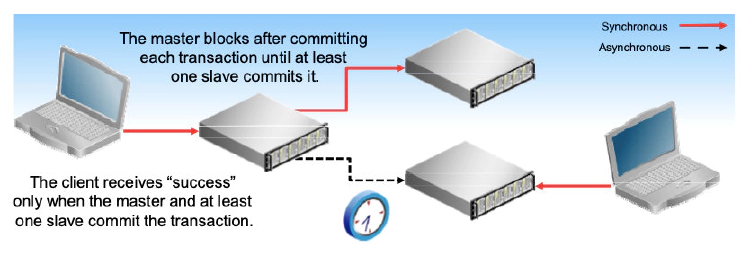
To enable semisynchronous replication, install a plugin on the master and on at least one slave. Use the following plugins: - rpl_semi_sync_master on a master - rpl_semi_sync_slave on a slave
You must also enable the following options: - rpl_semi_sync_master_enabled on a master - rpl_semi_sync_slave_enabled on a slave
If you enable semisynchronous replication on a master, it behaves asynchronously until at least one semisynchronous slave connects. During semisynchronous replication, the master blocks after committing a transaction until at least one semisynchronous slave acknowledges that it too has received the transaction. This means that at least one slave has received each transaction at the time the master reports success to the application. If the master crashes with data loss after committing a transaction and the application has reported success to the user, the transaction also exists on at least one slave.
Semisynchronous replication presents you with a trade-off between performance and data integrity. Transactions are slower when using semisynchronous replication than when using asynchronous replication because the master waits for a slave response before committing. The extra time taken by each transaction is at least the time it takes for:
- The TCP/IP roundtrip to send the commit to the slave
- The slave recording the commit in its relay log
- The master waiting for the slave’s acknowledgment of that commit
This means that semisynchronous replication works most effectively for servers that are physically co-located, communicating over fast networks. If the master does not receive a response from a semisynchronous slave within a timeout period, the master still commits the transaction but reverts to asynchronous mode. You can configure the timeout with the rpl_semi_sync_master_timeout variable, which contains a value measured in milliseconds. The default value is 10000, representing ten seconds.
FLUSH LOGS in Replication Environments
By default, the MySQL server writes FLUSH commands to the binary log so that statements are replicated to the slaves. To prevent this from happening, use the optional NO_WRITE_TO_BINLOG keyword or its alias LOCAL.
Replication Logs
Slave servers maintain information about replication events.
Relay logs: MySQL automatically manages the set of relay log files, removing files when it has replayed all events and creating a new file when the current file exceeds the maximum relay log file size (or max_binlog_size if max_relay_log_size is 0). The relay logs are stored in the same format as the binary logs; you can view them with mysqlbinlog. The slave maintains an index file to keep track of relay log files.
The relay log files are named [host_name]-relay-bin.[nnnnnn] by default, and the index file is named [host_name]-relay-bin.index. To make the server configuration immune to potential future hostname changes, change these host name prefixes by setting the options –relay-log and –relay-log-index.
Slave status logs: The slave stores information about how to connect to the master, and the most recently replicated log coordinates of the master’s binary log and the slave’s relay log.
There are two such logs:
- Master information: This log contains information about the master server, including information such as the host name and port, credentials used to connect, and the most recently downloaded log coordinates of the master’s binary log.
- Relay log information: This log contains the most recently executed coordinates of the relay log, and the number of seconds by which the slave’s replicated events are behind those of the master.
Slave status logs are stored in files or tables: — master.info and relay-log.info files by default. — slave_master_info and slave_relay_log_info tables in the mysql database.
Crash-Safe Replication
Binary logging is crash-safe. In case of Binary logging MySQL only logs complete events or transactions and use sync-binlog to improve safety. By default, the value of sync-binlog is 0, meaning the operating system writes to the file according to its internal rules. Set sync-binlog to 1 to force the operating system to write the file after every transaction, or set it to any larger number to write after that number of transactions. The slave status logs are stored in files by default. Use the master-info-file and relay-log-info-file options to set the file names. By default, the file names are master.info and relay-log.info, both stored in the data directory. If you store the slave status logs in files, a crash could happen at a point between logging an event and recording that event’s log coordinates in the status log. When the server restarts after such an event, the status file and binary log are inconsistent, and recovery becomes difficult.
When replicating data that uses a transactional storage engine such as InnoDB, store the status logs in transactional tables to improve performance and ensure crash-safe replication by changing the values of master-info-repository and relay-log-inforepository from FILE (the default) to TABLE. The tables are called slave_master_info and slave_relay_log_info, both stored in the mysql database, and both using the InnoDB engine to ensure transactional integrity and crash-safe behavior.
Replication Threads
MySQL creates threads on both the master and slave servers to perform the work of replication. When a slave connects successfully to a master, the master server launches a replication master thread, known as the Binlog dump thread, displayed as “Binlog Dump GTID” if the slave is configured to use the auto-positioning protocol (CHANGE MASTER TO MASTER_AUTO_POSITION). This thread sends events within the binary log to the slave as those events arrive, while the slave is connected. The master creates a Binlog dump thread for each connected slave.
By default, each slave launches two threads, known as the Slave I/O thread and the Slave SQL thread, respectively.
- The Slave I/O thread connects to the master, and reads updates from the Binlog dump thread into a local relay log.
- The Slave SQL thread executes the events within the relay log.
The default configuration, called single-threaded due to the single SQL thread processing the relay log, can result in slave lag, where the slave falls behind the master: The master applies changes in parallel if it has multiple client connections, but it serializes all events in its binary log. The slave executes these events sequentially in a single thread, which can become a bottleneck in high volume environments, or when the slave’s hardware is not powerful enough to deal with the volume of traffic in a single thread.
Multithreaded Slaves
MySQL supports multithreaded slaves to avoid some of the lag caused by single-threaded slaves. If you set the slave_parallel_workers variable to a value greater than zero on a slave, it creates that many worker threads. In that case, the Slave SQL thread does not execute events directly. Instead, it distributes events to the worker threads on a per-database basis. This makes multithreaded slaves particularly useful in environments where you replicate data in multiple databases.
This option can cause inconsistency between databases if worker threads perform parallel operations in an order different from how they were performed on the master, so you must ensure that data in different databases is independent. Data within one database, being replicated by a single thread, is guaranteed to be consistent.
If you set the slave_parallel_workers variable to a value larger than the number of databases used in replication, some worker threads remain idle. Similarly, if you replicate only one database across your servers, there is no benefit to using multithreaded slaves in your environment.
Controlling Slave Threads
You can start and stop the slave’s SQL and I/O threads with the START SLAVE and STOP SLAVE statements. Without arguments, these statements control both threads.
START SLAVE;
STOP SLAVE;
Control each thread individually by specifying IO_THREAD or SQL_THREAD as an argument. For example, you can temporarily stop the slave from querying the master by issuing the following statement on the slave:
STOP SLAVE IO_THREAD;
When starting a slave thread, you can choose to have the thread stop when it gets to a point specified in the UNTIL clause. You can specify this point using log coordinates, a GTID set, or the special SQL_AFTER_MTS_GAPS value, used with multithreaded slaves.
START SLAVE UNTIL SQL_AFTER_MTS_GAPS;
For example, the following statement starts the SQL thread on a slave until it executes the specified GTID from the relay log, at which point it stops:
START SLAVE SQL_THREAD UNTIL SQL_AFTER_GTIDS = 0ed18583-47fd-11e2-92f3-0019b944b7f7:338
To disconnect the slave from the master:
RESET SLAVE [ALL]
Resetting the Slave
Sometimes you might want to disconnect the slave from the master for a clean start. The RESET SLAVE command does the following:
- Clears master.info and relay.log repositories
- Deletes all the relay logs
- Starts a new relay log file
- Resets any MASTER_DELAY specified in the CHANGE MASTER TO statement to 0
- Retains connection parameters (only in MySQL 5.6 onwards), so you can restart the slave without executing CHANGE MASTER TO - Issue RESET SLAVE ALL to reset the connection parameters.
Monitoring Replication
Use the query “SHOW SLAVE STATUS” to monitor replication progress. Example for the query output:
mysql> SHOW SLAVE STATUS\G
***************** 1. row *********************
Slave_IO_State: Queueing master event to the relay log
...
Master_Log_File: mysql-bin.005
Read_Master_Log_Pos: 79
Relay_Log_File: slave-relay-bin.005
Relay_Log_Pos: 548
Relay_Master_Log_File: mysql-bin.004
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
...
Exec_Master_Log_Pos: 3769
...
Seconds_Behind_Master: 8
Slave_*_Running: The Slave_IO_Running and Slave_SQL_Running columns identify whether the slave’s I/O thread and SQL thread are currently running, not running, or running but not yet connected to the master. The respective possible values are Yes, No, or Connecting.
Master Log Coordinates: The Master_Log_File and Read_Master_Log_Pos columns identify the coordinates of the most recent event in the master’s binary log that the I/O thread has transferred. These columns are comparable to the coordinates shown when you execute SHOW MASTER STATUS on the master. If the values of Master_Log_File and Read_Master_Log_Pos are far behind those on the master, this indicates latency in the network transfer of events between the master and slave.
Relay Log Coordinates: The Relay_Log_File and Relay_Log_Pos columns identify the coordinates of the most recent event in the slave’s relay log that the SQL thread has executed. These coordinates correspond to coordinates in the master’s binary log identified by the Relay_Master_Log_File and Exec_Master_Log_Pos columns.
If the Relay_Master_Log_File and Exec_Master_Log_Pos columns’ output is far behind the Master_Log_File and Read_Master_Log_Pos columns representing the coordinates of the I/O thread, this indicates latency in the SQL thread rather than the I/O thread. That is, it indicates that copying the log events is faster than executing them.
On a multithreaded slave, Exec_Master_Log_Pos contains the position of the last point before any uncommitted transactions. This is not always the same as the most recent log position in the relay log, because a multithreaded slave might execute transactions on different databases in a different order from that represented in the binary log.
Seconds_Behind_Master: This column provides the number of seconds between the time stamp (on the master) of the most recent event in the relay log executed by the SQL thread and the real time of the slave machine. A delay of this type normally occurs when the master processes a large volume of events in parallel that the slave must process serially, or when the slave’s hardware is not capable of handling the same volume of events that the master can handle during periods of high traffic. If the slave is not connected to the master, this column is NULL.
Replication Slave I/O Thread States
Below is the most commonly seen I/O thread states displayed in the State column of the output of SHOW PROCESSLIST for a slave server I/O thread. These states also appear in the Slave_IO_State column displayed by SHOW SLAVE STATUS.
- Connecting to master: The thread is attempting to connect to the master.
- Waiting for master to send event: The thread has connected to the master and is waiting for binary log events to arrive. This can last for a long time if the master is idle. If the wait lasts for slave_read_timeout seconds, a timeout occurs. At that point, the thread considers the connection to be broken and attempts to reconnect.
- Queueing master event to the relay log: The thread has read an event and is copying it to the relay log so that the SQL thread can process it.
- Waiting to reconnect after a failed binlog dump request: If the binary log dump request failed (due to disconnection), the thread goes into this state while it sleeps, and then tries to reconnect periodically. The interval between retries can be specified using the –master-connect-retry option.
- Reconnecting after a failed binlog dump request: The thread is trying to reconnect to the master.
- Waiting to reconnect after a failed master event read: An error occurred while reading (due to disconnection). The thread is sleeping for masterconnect- retry seconds before attempting to reconnect.
- Reconnecting after a failed master event read: The thread is trying to reconnect to the master. When connection is established again, the state becomes Waiting for master to send event.
- Waiting for the slave SQL thread to free enough relay log space: This state shows that a non-zero relay_log_space_limit value is being used, and the relay logs have grown large enough so that their combined size exceeds this value. The I/O thread is waiting until the SQL thread frees enough space by processing relay log contents so that it can delete some relay log files.
Replication Slave SQL Thread States
The below list shows the most common states displayed in the State column for slave SQL threads and worker threads.
- Waiting for the next event in relay log: This is the initial state before Reading event from the relay log.
- Reading event from the relay log: The thread has read an event from the relay log so that the event can be processed.
- Making temp file: The thread is executing a LOAD DATA INFILE statement and is creating a temporary file containing the data from which the slave reads rows.
- Slave has read all relay log: waiting for the slave I/O thread to update it: The thread has processed all events in the relay log files and is now waiting for the I/O thread to write new events to the relay log.
- Waiting until MASTER_DELAY seconds after master executed event: The SQL thread has read an event but is waiting for the slave delay to lapse. This delay is set with the MASTER_DELAY option of CHANGE MASTER TO.
- Waiting for an event from Coordinator: On multithreaded slaves, a worker is waiting for the coordinator thread to assign a job to the worker queue.
Troubleshooting MySQL Replication
You can view the error log to troubleshoot any MySQL replication issue. The error log can provide you with enough information to identify and correct problems in replication.
1. Issue a SHOW MASTER STATUS statement on the master. Logging is enabled if the position value is non-zero. Verify that both the master and slave have a unique nonzero server ID value. The master and the slave must have different server IDs. 2. Issue a SHOW SLAVE STATUS command on the slave. The parameters Slave_IO_Running and Slave_SQL_Running display Yes when the slave is functioning correctly. The SHOW SLAVE STATUS statement returns information in several fields related to the most recent error encountered during replication.
- Last_IO_Error, Last_SQL_Error: The error message of the most recent error that caused, respectively, the I/O thread or SQL thread to stop. During normal replication, these fields are empty. If an error occurs and causes a message to appear in either of these fields, the error values also appear in the error log.
- Last_IO_Errno, Last_SQL_Errno: The error number associated with the most recent error that caused, respectively, the I/O or SQL thread to stop. During normal replication, these fields contain the number 0.
- Last_IO_Error_Timestamp, Last_SQL_Error_Timestamp: The time stamp of the most recent error that caused, respectively, the I/O thread or SQL thread to stop, in the format YYMMDD HH:MM:SS. During normal replication, these fields are empty.
The error log contains information about when replication begins and about any errors that occur during replication. For example, the following sequence shows a successful start and then a subsequent failure in replicating a user that already exists on the slave:
2012-12-16 11:13:21 8449 [Note] Slave I/O thread: connected to master
'[email protected]:3313',replication started in log 'FIRST' at position 4
2012-12-16 11:13:21 8449 [Note] Slave SQL thread initialized, starting
replication in log 'mysql-bin.000002' at position 108, relay log
'./slave-relay-bin.000003' position: 408
...
2012-12-16 16:42:53 8449 [ERROR] Slave SQL: Error 'Operation CREATE
USER failed for 'user'@'127.0.0.1'' on query. Default database:
'world_innodb'. Query: 'CREATE USER ‘user'@'127.0.0.1' IDENTIFIED BY
PASSWORD '*2447D497B9A6A15F2776055CB2D1E9F86758182F'', Error_code:
1396
2012-12-16 16:42:53 8449 [Warning] Slave: Operation CREATE USER failed
for 'user'@'127.0.0.1' Error_code: 1396
2012-12-16 16:42:53 8449 [ERROR] Error running query, slave SQL thread
aborted. Fix the problem, and restart the slave SQL thread with "SLAVE
START". We stopped at log 'mysql-bin.000002' position 460
The following sequence shows a failure of the I/O thread reading from the master’s binary log:
2012-12-16 16:48:13 8823 [Note] Slave I/O thread: connected to master
'[email protected]:3313',replication started in log 'mysql-bin.000002' at position 1172
2012-12-16 16:48:15 8823 [ERROR] Read invalid event from master: 'Found invalid event
in binary log', master could be corrupt but a more likely cause of this is a bug
2012-12-16 16:48:15 8823 [ERROR] Slave I/O: Relay log write failure: could not queue
event from master, Error_code: 1595
2012-12-16 16:48:15 8823 [Note] Slave I/O thread exiting, read up to log 'mysqlbin.
000003', position 4
- Use mysqlrplcheck to ensure that servers meet the prerequisites for replication. Issue a SHOW PROCESSLIST command on the master and slave. Review the state of the Binlog dump, I/O, and SQL threads.
- For a slave that suddenly stops working, check the most recently replicated statements. The SQL thread stops if an operation fails due to a constraint problem or other error. The error log contains events that cause the SQL thread to stop. Verify that the slave data has not been modified directly (outside of replication).
SHOW PROCESSLIST on Slave
I/O thread states connecting to master:
- Verify privileges for the user being used for replication on the master.
- Verify that the hostname and port are correct for the master.
- Verify that networking has not been disabled on the master or the slave (with the –skip-networking option).
- Attempt to ping the master to verify that the slave can reach the master.