Beginners Guide to Oracle Data Guard
Oracle Data Guard is a central component of an integrated Oracle Database High Availability (HA) solution set that helps organizations ensure business continuity by minimizing the various kinds of planned and unplanned downtime that can affect their businesses. Oracle Data Guard is a management, monitoring, and automation software infrastructure that works with a production database and one or more standby databases to protect your data against failures, errors, and corruptions that might otherwise destroy your database. It protects critical data by providing facilities to automate the creation, management, and monitoring of the databases and other components in a Data Guard configuration. It automates the process of maintaining a copy of an Oracle production database (called a standby database) that can be used if the production database is taken offline for routine maintenance or becomes damaged.
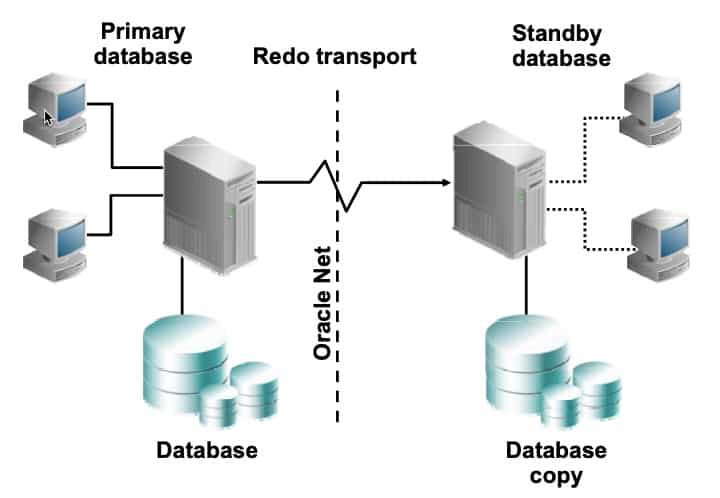
In a Data Guard configuration, a production database is referred to as a primary database. A standby database is a synchronized copy of the primary database. By using a backup copy of the primary database, you can create from 1 to 30 standby databases. The standby databases, together with the primary database, make up a Data Guard configuration. All Data Guard standby databases can enable up-to-date read access to the standby database while redo being received from the primary database is applied. This makes all standby databases excellent candidates for relieving the primary database of the overhead of supporting read-only queries and reporting.
Types of Standby Databases
Physical Standby Database
A physical standby database is physically identical to the primary database, with on-disk database structures that are identical to the primary database on a block-for-block basis. The physical standby database is updated by performing recovery using redo data that is received from the primary database. Oracle Database12c enables a physical standby database to receive and apply redo while it is open in read-only mode.
Logical Standby Database
A logical standby database contains the same logical information (unless configured to skip certain objects) as the production database, although the physical organization and structure of the data can be different. The logical standby database is kept synchronized with the primary database by transforming the data in the redo received from the primary database into SQL statements and then executing the SQL statements on the standby database. This is done with the use of LogMiner technology on the redo data received from the primary database. The tables in a logical standby database can be used simultaneously for recovery and for other tasks such as reporting, summations, and queries.
Snapshot Standby Database
A snapshot standby database is a database that is created by converting a physical standby database into a snapshot standby database. The snapshot standby database receives redo from the primary database, but does not apply the redo data until it is converted back into a physical standby database. The snapshot standby database can be used for updates, but those updates are discarded before the snapshot standby database is converted back into a physical standby database. The snapshot standby database is appropriate when you require a temporary, updatable version of a physical standby database.
Types of Data Guard Services
The following types of services are available with Data Guard:
Redo transport services: Control the automated transmittal of redo information from the primary database to one or more standby databases or archival destinations.
Apply services: Control when and how data is applied to the standby database.:
- Redo Apply: Technology used for physical standby databases. Redo data is applied on the standby database by using Oracle media recovery.
- SQL Apply: Technology used for logical standby databases. The received redo data is first transformed into SQL statements, and then the generated SQL statements are executed on the logical standby database.
Role management services: A database operates in one of two mutually exclusive roles: primary or standby. Role management services operate in conjunction with redo transport services and apply services to change these roles dynamically as a planned transition (called a switchover operation) or as a result of database failure due to a failover operation.
Role Transitions: Switchover and Failover
Data Guard enables you to change the role of a database dynamically by issuing SQL statements or by using either of the Data Guard broker’s interfaces. Data Guard supports two role-transition operations:
Switchover: The switchover feature enables you to switch the role of the primary database to one of the available standby databases. The chosen standby database becomes the primary database, and the original primary database then becomes a standby database.
Failover: You invoke a failover operation when a catastrophic failure occurs on the primary database. During a failover operation, the failed primary database is removed from the Data Guard environment, and a standby database assumes the primary database role. You invoke the failover operation on the standby database that you want to failover to the primary role. You can also enable fast-start failover, which allows Data Guard to automatically and quickly failover to a previously chosen synchronized standby database.
Databases that are disabled after a role transition are not removed from the broker configuration, but they are disabled in the sense that the databases are no longer managed by the broker. To reenable broker management of these databases, you must reinstate or re-create the databases.
Oracle Data Guard Broker Framework
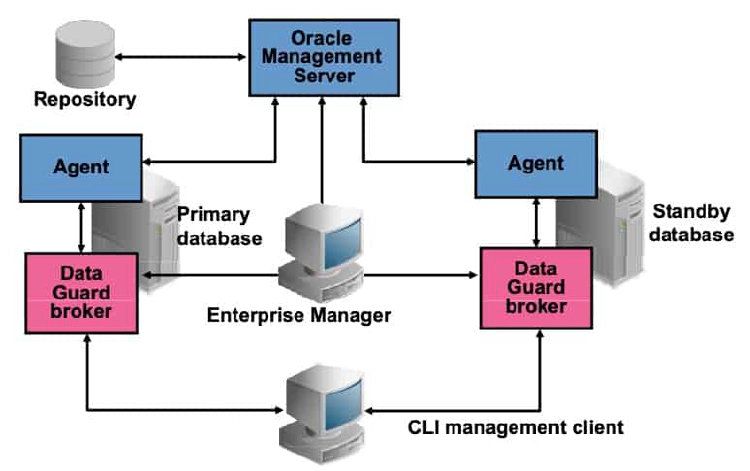
The Oracle Data Guard broker is a distributed management framework that automates and centralizes the creation, maintenance, and monitoring of Data Guard configurations. After creating the Data Guard configuration, the broker monitors the activity, health, and availability of all systems in the configuration.
The benefits of using Oracle Data Guard broker include:
- Enhanced disaster protection
- Higher availability and scalability with Oracle Real Application Clusters (Oracle RAC) Databases
- Automated creation of a Data Guard configuration
- Easy configuration of additional standby databases
- Simplified, centralized, and extended management
- Simplified switchover and failover operations
- Fast Application Notification (FAN) after failovers
- Built-in monitoring and alert and control mechanisms
- Transparency to the application
Choosing an Interface for Administering a Data Guard Configuration
You can use Oracle Enterprise Manager Cloud Control or the Data Guard broker’s own specialized command-line interface (DGMGRL) to take advantage of the broker’s management capabilities. Enterprise Manager Cloud Control provides a web-based interface that combines with the broker’s centralized management and monitoring capabilities so that you can easily view, monitor, and administer primary and standby databases in a Data Guard configuration.
You can also use DGMGRL to control and monitor a Data Guard configuration. You can perform most of the activities that are required to manage and monitor the databases in the configuration from the DGMGRL prompt or in scripts. If you do not create a Data Guard broker configuration, you can manage your standby databases by using SQL commands.
Oracle Data Guard: Architecture (Overview)
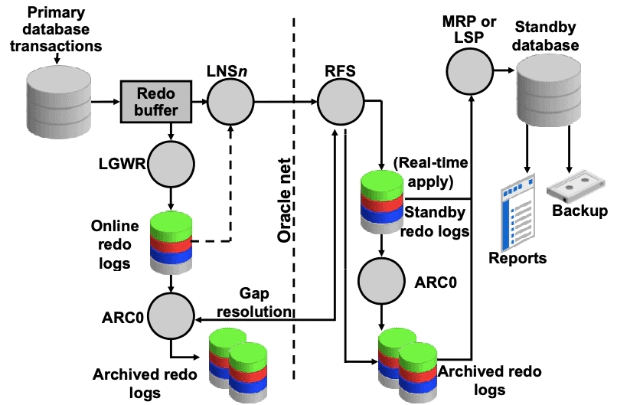
Oracle Data Guard leverages the existing database redo-generation architecture to keep the standby databases in the configuration synchronized with the primary database. By using the existing architecture, Oracle Data Guard minimizes its impact on the primary database. Oracle Data Guard uses several processes to achieve the automation that is necessary for disaster recovery and high availability. Some of these processes support Oracle Database in general, and other processes are specific to a Data Guard environment.
Primary Database Processes
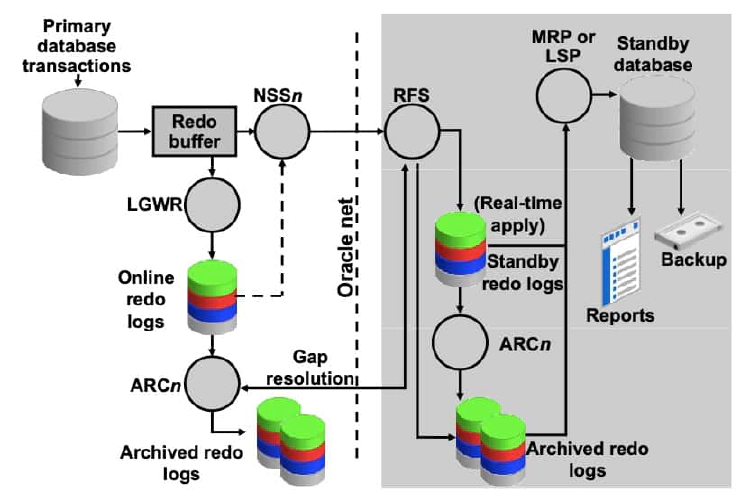
On the primary database, Data Guard uses the following processes:
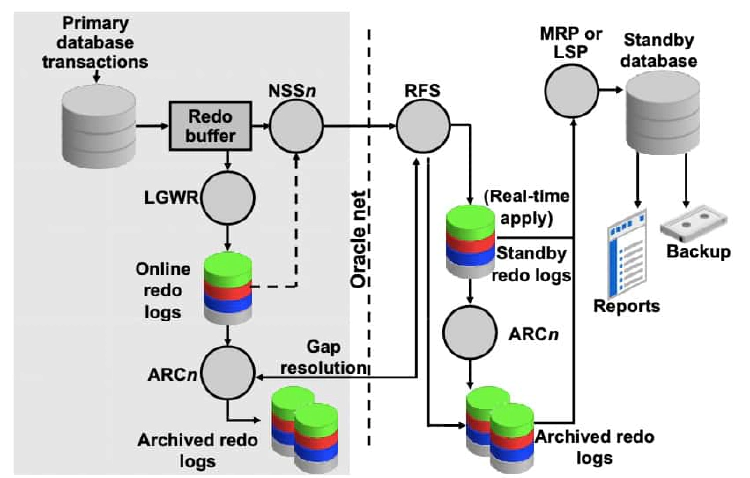
Log writer (LGWR)
LGWR collects transaction redo information and updates the online redo logs. For each synchronous (SYNC) standby database, LGWR passes the redo to an NSS (Network Server SYNC) process, which ships the redo directly to the remote file server (RFS) process on the standby database. LGWR waits for confirmation from the NSS process before acknowledging the commit. For asynchronous (ASYNC) standby databases, independent redo transport slave processes (TTnn) read the redo from either the redo log buffer in memory or the online redo log file, and then ship the redo to its standby database. Other than starting the asynchronous TTnn processes, LGWR has no interaction with any asynchronous standby destination.
Archiver (ARCn)
The ARCn process creates a copy of the online redo log files locally for use in a primary database recovery operation. ARCn is also responsible for shipping redo data to an RFS process at a standby database and for proactively detecting and resolving gaps on all standby databases. There can be 30 archiver processes. The default value is four.
Standby Database Processes
On the standby database, Data Guard uses the following processes:
Remote file server (RFS)
RFS receives redo information from the primary database and can write the redo into standby redo logs or directly to archived redo logs. Each NSSn and ARCn process from the primary database has its own RFS process. Note: The use of standby redo logs is discussed in more detail in the lesson titled “Creating a Physical Standby Database by Using SQL and RMAN Commands.”
Archiver (ARCn)
The ARCn process archives the standby redo logs.
Managed recovery (MRP)
For physical standby databases only, MRP applies archived redo log information to the physical standby database. If you start managed recovery with the ALTER DATABASE RECOVER MANAGED STANDBY DATABASE SQL statement, this foreground session performs the recovery. If you use the optional DISCONNECT clause, the MRP background process starts. If you use the Data Guard broker to manage your standby databases, the broker always starts the MRP background process for a physical standby database.
Logical standby (LSP)
For logical standby databases only, LSP controls the application of archived redo log information to the logical standby database.
Physical Standby Database: Redo Apply Architecture
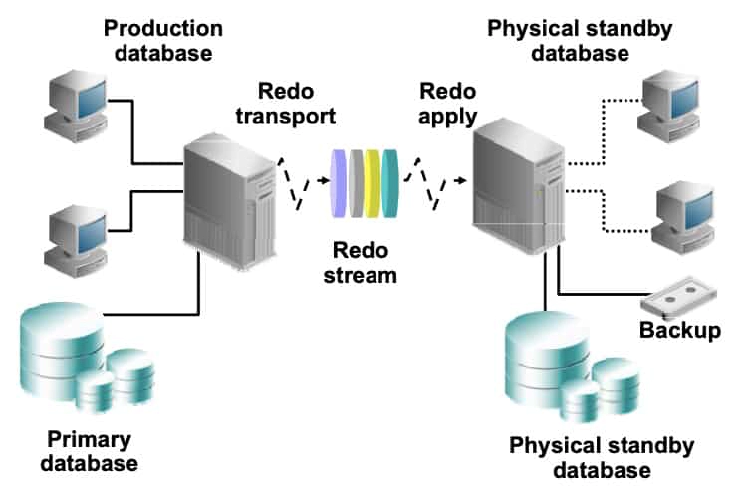
The Data Guard physical standby Redo Apply architecture consists of:
- A production (primary) database, which is linked to one or more standby databases (up to 30) that are identical copies of the production database. The limit of 30 standby databases is imposed by the LOG_ARCHIVE_DEST_n parameter. In Oracle Database 12c Release 1 (12.1), the maximum number of destinations is 31. One is used as the local archive destination, leaving the other 30 for uses such as the Far Sync or standby databases.
- The standby database, which is updated by redo that is automatically shipped from the primary database. The redo can be shipped as it is generated or archived on the primary database. Redo is applied to each standby database by using Oracle media recovery. During planned downtime, you can perform a switchover to a standby database. When a failure occurs, you can perform a failover to one of the standby databases. The physical standby database can also be used to back up the primary database.
Logical Standby Database: SQL Apply Architecture
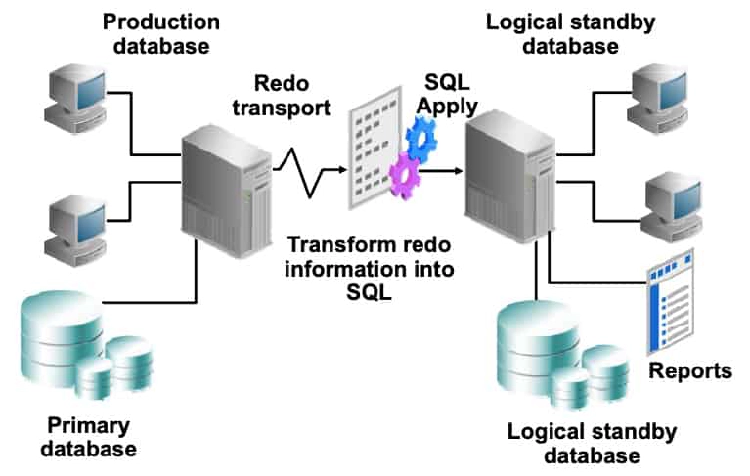
In a logical standby database configuration, Data Guard SQL Apply uses redo information shipped from the primary system. However, instead of using media recovery to apply changes (as in the physical standby database configuration), the redo data is transformed into equivalent SQL statements by using LogMiner technology. These SQL statements are then applied to the logical standby database. The logical standby database is open in read/write mode and is available for reporting capabilities. By opening the logical standby database in read/write mode, additional reporting structures such as indexes or materialized views can be created that do not exist in the primary database.
A logical standby database can be used to perform rolling database upgrades, thereby minimizing down time when upgrading to new database patch sets or full database releases.
Automatic Gap Detection and Resolution
If connectivity is lost between the primary database and one or more standby databases, redo data that is being generated on the primary database cannot be sent to those standby databases. When a connection is reestablished, Data Guard automatically detects that there are missing archived redo log files (referred to as a gap), and then automatically transmits the missing archived redo log files to the standby databases by using the ARCn processes. The standby databases are synchronized with the primary database without manual intervention by the DBA.
Data Protection Modes
Data Guard provides three high-level modes of data protection that you can configure to balance cost, availability, performance, and transaction protection. You can configure the Data Guard environment to maximize data protection, availability, or performance.
Maximum Protection
This protection mode guarantees that no data loss occurs if the primary database fails. For this level of protection, the redo data that is needed to recover each transaction must be written to both the local online redo log and the standby redo log (used to store redo data received from another database) on at least one standby database before the transaction commits. To ensure that data loss does not occur, the primary database shuts down if a fault prevents it from writing its redo stream to at least one remote standby redo log.
Maximum Availability
This protection mode provides the highest possible level of data protection without compromising the availability of the primary database. As with maximum protection mode, a transaction does not commit until the redo needed to recover that transaction is written to the local online redo log and to at least one remote standby redo log. Unlike maximum protection mode, the primary database does not shut down if a fault prevents it from writing its redo stream to a remote standby redo log. Instead, the primary database operates in an unsynchronized mode until the fault is corrected and all the gaps in the redo log files are resolved. When all the gaps are resolved and the primary database is synchronized with the standby database, the primary database automatically resumes operating in maximum availability mode.
This mode guarantees that no data loss occurs if the primary database fails, but only if a second fault does not prevent a complete set of redo data from being sent from the primary database to at least one standby database.
Maximum Performance (Default)
The default protection mode provides the highest possible level of data protection without affecting the performance of the primary database. This is accomplished by allowing a transaction to commit as soon as the redo data needed to recover that transaction is written to the local online redo log. The primary database’s redo data stream is also written to all ASYNC standby databases and is written asynchronously with respect to the commitment of the transactions that create the redo data.