Beginners Guide to MySQL Architecture
MySQL’s architecture is very different from that of other database servers and makes it useful for a wide range of purposes. MySQL is not perfect, but it is flexible enough to work well in very demanding environments, such as web applications. At the same time, MySQL can power embedded applications, data warehouses, content indexing, and delivery software, highly available redundant systems, online transaction processing (OLTP), and much more.
To get the most from MySQL, you need to understand its design so that you can work with it, not against it. MySQL is flexible in many ways. For example, you can configure it to run well on a wide range of hardware, and it supports a variety of data types. However, MySQL’s most unusual and important feature is its storage-engine architecture, whose design separates query processing and other server tasks from data storage and retrieval.
MySQL client/server mode
A MySQL installation has the following required architectural components: the MySQL server, client programs, and MySQL non-client programs. A central program acts as a server, and the client programs connect to the server to make data requests.
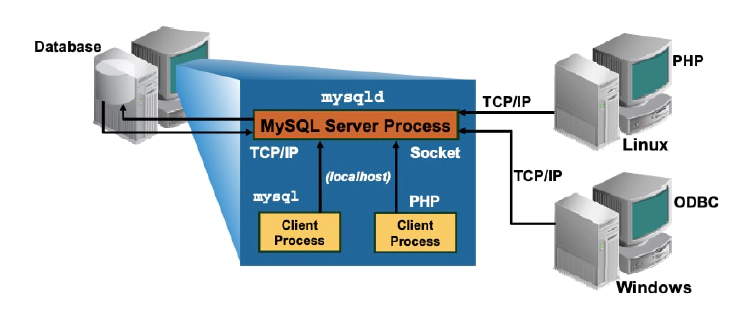
MySQL client/server communication is not limited to environments where all computers run the same operating system.
- Client programs can connect to the server running on the same host or on a different host.
- Client/server communication can occur in environments where computers run different operating systems.
Client Programs
These programs are executed from the prompt of a command interpreter:
shell> mysql [options]
Use these client programs to perform the following actions:
- mysql: Issue queries and view results.
- mysqladmin: Administer the server.
- mysqlcheck: Check the integrity of database tables.
- mysqldump: Create logical backups.
- mysqlimport: Import text data files.
- mysqlshow: Show database, table, and column information.
- mysqlslap: Emulate client load.
The mysql client program is commonly known as the command-line interface (CLI). For more information about client programs, see the MySQL Reference Manual: http://dev.mysql.com/doc/mysql/en/programs-client.html.
Administrative and Utility Programs
There are many more programs available. To avoid loss or corruption of data, some of the programs require that you shut down the server and/or make a back up of your current tables prior to execution. For more information about administrative and utility programs, see the MySQL Reference Manual: http://dev.mysql.com/doc/mysql/en/programs-admin-utils.html.
Some of the administrative and utility programs are lusted below:
- innochecksum:Check an InnoDB tablespace file offline.
- mysqldumpslow:Summarize the slow query log files.
- mysqlbinlog:Display the binary log files.
MySQL Server
Note the difference between a server and a host: Server: A software program (mysqld) with a version number and a list of features. Host: The physical machine on which the server program runs, which includes the following:
- Its hardware configuration
- The operating system running on the machine
- Its network addresses
Multiple mysqld instances can run simultaneously on one host. The configuration of the MySQL server evolves from one product version to the next. Always consult the product documentation for the most up-to-date configuration information.
MySQL Server
- Is the database server program called mysqld
- Is not the same as a “host”
- Is a single process and is multithreaded
- Manages access to databases on disk and in memory
- Supports simultaneous client connections
- Supports multiple storage engines
- Supports both transactional and nontransactional tables
- Uses memory in the form of: Caching and Buffering
Server Process
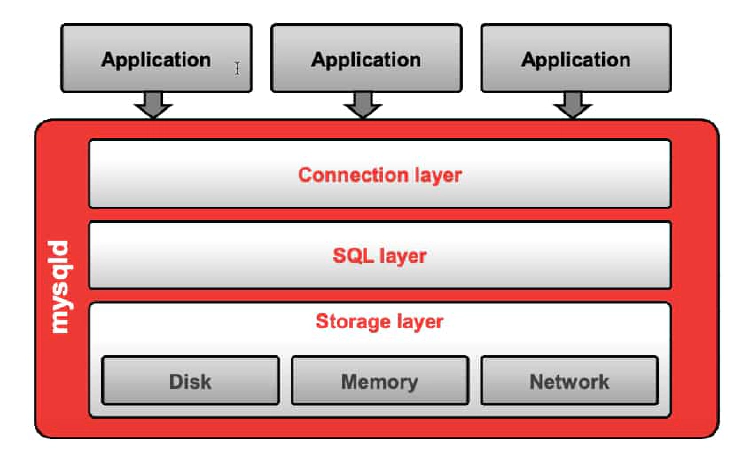
The mysql (server program) process can be sliced into the following three layers:
- Connection layer: Handles connections. This layer exists on all server software (Web/mail/LDAP server).
- SQL layer: Processes SQL queries that are sent by connected applications.
- Storage layer: Handles data storage. Data can be stored in different formats and structures on different physical media.
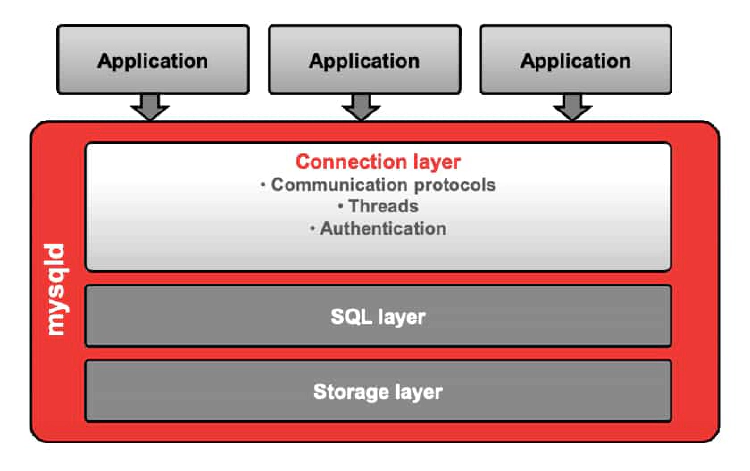
Connection Layer
The connection layer accepts connections from applications over several communication protocols:
- TCP/IP
- UNIX sockets
- Shared memory
- Named pipes
TCP/IP works across the network. The other protocols listed above support only local connections when the client and server are running on the same machine. This layer maintains one thread per connection. This thread handles query execution. Before a connection can begin sending SQL queries, the connection is authenticated by verification of username + password + client host.
MySQL uses DNS (Domain Naming System) to resolve the names of hosts that connect using TCP/IP protocol, storing them in a host cache. For large networks that exhibit performance problems during name resolution, disable DNS with the –skip-name-resolve option, or increase the value of the –host-cache-size option.
Communication Protocols
Protocols are implemented in the client libraries and drivers. The speed of a connection protocol varies with the local settings.
| Protocol | Types of Connections | Supported Operating Systems |
|---|---|---|
| TCP/IP | Local, remote | All |
| UNIX socket file | Local only | UNIX only |
| Shared memory | Local only | Windows only |
| Named pipes | Local only | Windows only |
- TCP/IP(Transmission Control Protocol/Internet Protocol): The suite of communication protocols used to connect hosts on the Internet. In the Linux operating system, TCP/IP is built-in and is used by the Internet, making it the standard for transmitting data over networks. This is the best connection type for Windows.
- UNIX socket: A form of inter-process communication used to form one end of a bidirectional communication link between processes on the same machine. A socket requires a physical file on the local system. This is the best connection type for Linux.
- Shared memory: An efficient means of passing data between programs. One program creates a memory portion that other processes (if permitted) can access. This Windows explicit “passive” mode works only within a single (Windows) machine. Shared memory is disabled by default. To enable shared-memory connections, you must start the server with the –shared-memory option.
- Named pipes:The use of named pipes is biased toward client/server communication, where they work much like sockets. Named pipes support read/write operations, along with an explicit “passive” mode for server applications. This protocol works only within a single (Windows) machine. Named pipes are disabled by default. To enable named-pipe connections, you must start the server with the –enable-named-pipe option.
SQL Layer
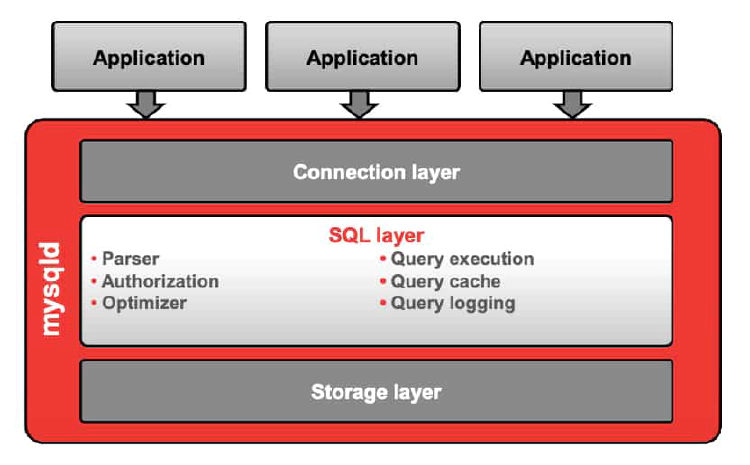
After a connection is established, the following processes are handled by the MySQL server:
- Authorization and parser:The parser validates the correct syntax, and then authorization verifies that the connected user is allowed to run a particular query.
- Optimizer:Creates the execution plan for each query, which is a step-by-step instruction set on how to execute the query in the most optimal way. Determining which indexes are to be used, and in which order to process the tables, is the most important part of this step.
- Query execution:Fulfills the execution plan for each query
- Query cache:Optionally configurable query cache that can be used to memorize (and immediately return) executed queries and results
- Query logging:Can be enabled to track executed queries
Storage Layer
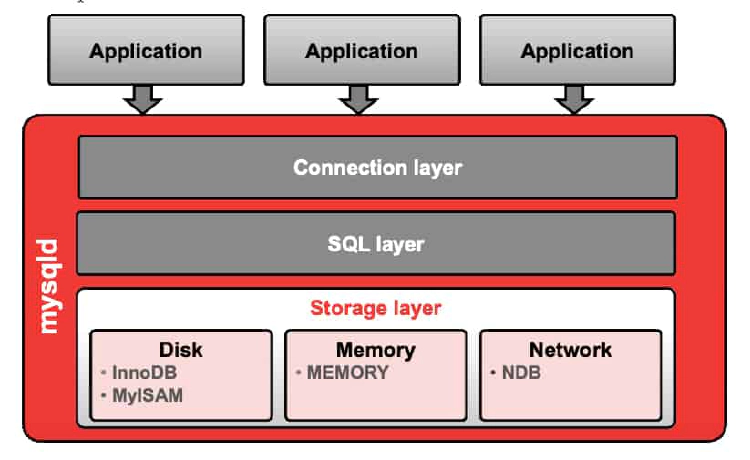
With MySQL, you can use different types of storage called “storage engines.” Data can be stored on disk, memory, and network. Each table in a database can use any of the available storage engines. Disk storage is cheap and persistent, whereas memory is much faster.
InnoDB is the default storage engine. It provides transactions, full-text indexing, and foreign key constraints, and is thus useful for a wide mix of queries. It is multipurpose and supports read-intensive, read/write, and transactional workloads.
Other storage engines include:
- MyISAM: Useful for mostly read and little update of data
- **MEMORY:**Stores all data in memory
- **NDB:**Used by MySQL Cluster to provide redundant scalable topology for highly available data
Storage Engine: Overview
Storage engines are server components that act as handlers for different table types. Storage engines are used to:
- Store data
- Retrieve data
- Find data through an index
A client retrieves data from tables or changes data in tables by sending requests to the server in the form of SQL statements. The server executes each statement by using the two-tier processing model.
Clients normally do not need to be concerned about which engines are involved in processing SQL statements. Clients can access and manipulate tables by using statements that are the same no matter which engine manages them. Exceptions to this engine-independence of SQL statements include the following:
- CREATE TABLE has an ENGINE option that specifies which storage engine to use on a per-table basis.
- ALTER TABLE has an ENGINE option that enables the conversion of a table to use a different storage engine.
- Some index types are available only for particular storage engines. For example, only the InnoDB and MyISAM engines support full-text indexes.
- COMMITand ROLLBACK operations affect only tables that are managed by transactional storage engines such as InnoDB and NDB.
Features Dependent on Storage Engine
The following properties are dependent on the storage engine:
- Storage medium: A table storage engine can store data on disk, in memory, or over a network.
- Transactional capabilities: Some storage engines support full ACID transactional capability, while others may have no transactional support. Note: ACID is discussed in the lesson titled “Transactions and Locking.”
- **Locking: **Storage engines may use different locking granularity (such as table-level or row-level locks) and mechanisms to provide consistency with concurrent transactions.
- Backup and recovery: May be affected by how the storage engine stores and operates the data
- Optimization: Different indexing implementations may affect optimization. Storage engines use internal caches, buffers, and memory in different ways to optimize performance.
- Special features: Certain engine types have features that provide full-text search, referential integrity, and the ability to handle spatial data.
The optimizer may need to make different choices depending on the storage engine, but this is all handled through a standardized interface (API) that each storage engine supports.
How MySQL Uses Disk Space

Program files are stored under server installation directories, along with the data directory. The program executable and log files are created by the execution of the various client, administrative, and utility programs. The primary use of disk space is the data directory.
- Server log files and status files contain information about statements that the server processes. Logs are used for troubleshooting, monitoring, replication, and recovery. - InnoDB log files for all databases reside at the data directory level. - InnoDB System Table space contains the data dictionary, undo log, and buffers. - Each database has a single directory under the data directory, regardless of what types of tables are created in the database. The database directories store the following:
- Data files:Storage engine–specific data files. These files can also include metadata or index information, depending on the storage engine used.
- Format files (.frm):Contain a description of each table and/or view structure, located in the corresponding database directory
- Triggers:Named database objects that are associated with a table and are activated when a particular event occurs for the table
- The location of the data directory depends on the configuration, operating system, installation package, and distribution. A typical location is /var/lib/mysql. - MySQL stores the system database (mysql) on disk. mysql contains information such as users, privileges, plugins, help lists, events, time-zone implementations, and stored routines.
How MySQL Uses Memory
Memory allocation can be divided into the following two categories:
1. Global(per-instance memory): Allocated once when the server starts and freed when the server shuts down. This memory is shared across all sessions. When all the physical memory has been used up, the operating system starts swapping. This has an adverse effect on MySQL server performance and can cause the server to crash
2. Session(per-session memory): Dynamically allocated per session (sometimes referred to as thread). This memory can be freed when the session ends or is no longer needed. This memory is mostly used for handling query results. The sizes of the buffers used are per connection. For instance, a read_buffer of 10 MB with 100 connections means that there could be a total of 100*10 MB used for all read buffers simultaneously.
Memory Structures
Server allocates memory in three different categories:
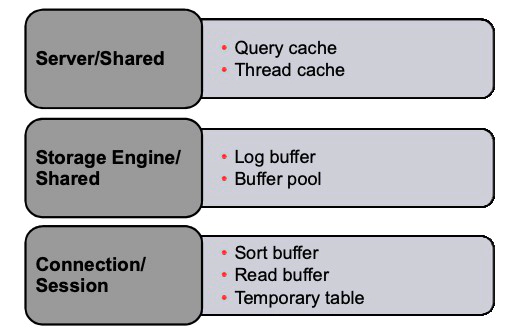
The server allocates memory for many kinds of data as it runs.
1. Thread cache: Threads are used in MySQL (and other programs) to split the execution of the application into two or more simultaneously running tasks. An individual thread is created for each client that connects to the MySQL server to handle that connection.
2. Buffers and caches: Buffers and caches provide a data management subsystem and support fast-access items such as grant table buffers, storage engine buffers such as InnoDB’s log buffers, and table open caches that hold descriptors for open tables. A query cache is also used to speed up the processing of queries that are issued repeatedly.
If you use the MEMORY storage engine, MySQL uses the main memory as the principal data store. Other storage engines may also use the main memory for data storage, but MEMORY is unique for being designed not to store data on disk.
Connection/Session
1. Internal temporary tables: In some cases of query execution, MySQL creates a temporary table to resolve the query. The temporary table can be created in memory or on disk depending on its size or contents or on the query syntax.
2. Client-specific buffers : Are specifically designed to support the individual clients that are connected. Examples of the buffers include:
- Communications buffer for exchanging information
- Table read buffers (including buffers that support joins)
- Sort operations
MySQL Plugin Interface
Currently, the plugin API supports:
- Full-text parser plugins that can be used to replace or augment the built-in full-text parser. For example, a plugin can parse text into words by using rules that differ from those used by the built-in parser. This is useful to parse text with characteristics different from those expected by the built-in parser.
- Storage engines that provide low-level storage, retrieval, and data indexing to the server
- Information schema plugins. An information schema plugin appears as a table in the MySQL INFORMATION_SCHEMAdatabase. The INFORMATION_SCHEMAdatabase is discussed later in more detail.
- A Daemon plugin starts a background process that runs within the server (for example, to perform heartbeat processing at regular intervals).
The plugin interface requires the PLUGINS table in the mysql database. This table is created as part of the MySQL installation process.