Beginners Guide to MySQL Partitioning
Partitioning
A partition is the division of a database, or its constituting elements, into distinct independent parts. MySQL supports horizontal partitioning. This post focuses on the MySQL partitioning technique known as “horizontal partitioning,” as illustrated in the figure below.
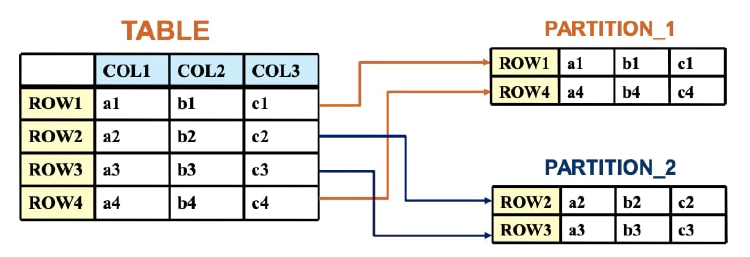
Physical partitioning is used when large tables are taxing the available disk space, and additional space is needed to store the table data. Table files can be placed in multiple locations, rather than forcing the data onto an overloaded disk. This technique is storage engine–dependent.
Partitioning Analogy
The “moving” analogy:
- Do you want to put everything from the living room into one giant box?
- How about putting items in several smaller boxes, by type?
- You have now partitioned your belongings!
The “moving” analogy is being used to portray partitioning. Suppose that you are moving out of your home. You could put all the things from your living room in one big box. However, that would not be very practical. It would be very difficult for you to find individual items. And it would be a very large and heavy box! It would be much better to use several boxes to hold all your items, and to categorize those boxes according to type. For example, you could have a box labeled “Books” for all your books, a box for “CDs,” a box for “Movies,” and so on. Now you have partitioned your belongings into specific boxes.
MySQL-Specific Partitioning
MySQL partitioning allows you to distribute portions of individual tables across your physical storage, according to rules that you can set largely as needed. Each partition is stored as a separate unit, much like a table. The way that MySQL accomplishes this is as follows:
1. The division of data is accomplished with a partitioning function, which in MySQL can be a simple matching against a set of ranges or value lists, an internal hashing function, or a linear hashing function.
2. The function is selected according to the partitioning type specified by the user, and takes the value of a user-supplied expression.
3. The expression can be either an integer column value, or a function acting on one or more column values and returning an integer.
- The expression must return NULL or an integer value.
- With the use of RANGE/LIST COLUMNS, the expression can be one or more columns of the following data types: INTs, DATE, DATETIME, CHAR, VARCHAR, BINARY, and VARBINARY.
4. This value determines which partition each record should be stored in, according to the partition definition(s).
Partitioning Types
MySQL supports several types of partitioning:
- RANGE: Ranges should be contiguous but not overlapping, and are defined using the VALUES LESS THAN operator.
- LIST: As in partitioning by RANGE, each partition must be explicitly defined.
- HASH: Operating on column values in rows to be inserted into the table
- KEY: Similar to HASH, except that only one or more columns to be evaluated are supplied, and the MySQL server provides a hashing function. It works on all allowed column types.
- COLUMNS: Variants on RANGE and LIST partitioning. COLUMNS partitioning enables the use of one or more columns in partitioning keys. All of these columns are taken into account both for the purpose of placing rows in partitions and for the determination of which partitions are to be checked for matching rows in partition pruning - RANGE COLUMNS and LIST COLUMNS partitioning support the use of non-integer columns (and other data types listed earlier) for defining value ranges or list members.
- LINEAR: MySQL also supports linear hashing, which differs from regular hashing in that linear hashing uses a linear powers-of-two algorithm whereas regular hashing employs the modulus of the hashing function’s value.
Partitioning Support
If the MySQL binary is built with partitioning support, you do not need to take any further action to enable the binary (for example, no special entries are required in your my.cnf file). If you do not see the partition plugin with the Status value ACTIVE listed in the output of SHOW PLUGINS, then your version of MySQL does not support partitioning.
mysql> SHOW PLUGINS\G
...
*********************** 43. row ***********************
Name: partition
Status: ACTIVE
Type: STORAGE ENGINE
Library: NULL
License: PROPRIETARY
...
How to disable partitioning support:
shell> mysqld --skip-partition
The partition plugin now has the value DISABLED.
Improving Performance with Partitioning
When you split data into logically grouped tables, a query has fewer records to search. This greatly improves the speed. Partitioning addresses some potential problems specific to large tables, such as slow runtimes for maintenance operations (for example, OPTIMIZE and REPAIR) and slow runtime when deleting unnecessary rows.
It is natural to want to partition tables according to date and time values. For example, you might want to segregate a table of store orders by year, quarter, or month. With MySQL, you can use partitioning schemes that are based on dates and times, making your queries more efficient.
Improving Performance with Partitioning: Pruning
“Pruning” happens when the MySQL optimizer deduces that the rows it needs to access to execute a particular query reside in a limited number of partitions. It searches only the partitions that fit the criteria of the query.
As the first example below shows, suppose that you have a bookstore and you have a database containing the entire inventory of books in your store. This database has tables for each category of books. A customer comes in to your store and asks for a list of all the books in the category of medicine, published between the years of 1990 and 2007. Because you took advantage of partitioning and have your medicine table partitioned by year, you can run a query that includes only those years. The optimizer “prunes” the search to scan only the 1990–2007 partitions, saving a huge amount of time and effort. (Note that MySQL does not transform the actual table data in any way.)
SELECT title FROM book
WHERE category = 'medicine'
AND published > 1990 AND published < 2007;
You can also perform explicit partition selection in statements that reference table data. For example, if you know that p0 includes all books published before 2007, you can explicitly state the partition to allow the optimizer to ignore other partitions. You can select multiple partitions and subpartitions by providing a list—for example PARTITION(p0, p2sp1).
Perform explicit partition selection:
SELECT title FROM book PARTITION(p0)
WHERE category = 'medicine'
AND published > 1990;
Explicit partition selection also works with INSERT, REPLACE, UPDATE, DELETE, and LOAD statements, although if you are adding or changing data in a partition, you must ensure that the new data meets the partitioning criteria for that partition.
Performance Challenges with Partitioning
All partitions must be opened when opening a partitioned table. This is a minor problem because opened tables are cached in the table cache.
Pruning presents specific restrictions: - Pruning is less efficient on indexed columns because it avoids only one index lookup per partition. - The effect of pruning is much greater for non-indexed columns.
- A query with a non-indexed column in its WHERE clause might require a full table scan.
- A partition scan takes a fraction of the time that a table scan takes.
Basic Partition Syntax
Create partitioned tables by using the PARTITION BY clause in the CREATE TABLE statement. PARTITION BY comes after all parts of CREATE TABLE:
CREATE TABLE [table_name] ([table_column_options])
ENGINE=[engine_name]
PARTITION BY [type] ([partition_expression]);
The partitioning type is followed by a partitioning expression in parentheses. Depending on the type of partitioning you use and your requirements, this expression can be the name of a table column, a simple mathematical expression involving one or more columns, or a comma-separated list of column names.
PARTITION BY types as included in their corresponding syntax:
- PARTITION BY RANGE …
- PARTITION BY RANGE COLUMNS …
- PARTITION BY LIST …
- PARTITION BY LIST COLUMNS …
- PARTITION BY HASH …
- PARTITION BY LINEAR HASH …
- PARTITION BY KEY …
- PARTITION BY LINEAR KEY …
RANGE Partitioning
In case of Range Partition, rows with column or expression values falling within a specified range are assigned to a given partition. For example, suppose you have a table that stores data related to its orders, and you want to specify that orders with id numbers less than 10,000 be stored in one partition, orders with id numbers between 10,000 and 19,999 in another, orders with id numbers between 20,000 and 29,999 in another, and so on.
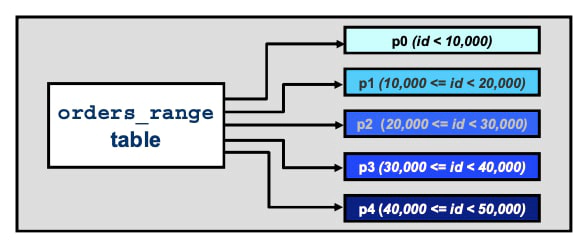
In other words, you partition the table based on contiguous ranges of values. RANGE partitioning is a good fit for such a partitioning scheme. For this case, you would use the following syntax to create a new table that is set up for range partitioning:
mysql> CREATE TABLE orders_range (
-> id INT AUTO_INCREMENT PRIMARY KEY,
-> customer_surname VARCHAR(30),
-> store_id INT, salesperson_id INT,
-> order_date DATE, note VARCHAR(500)
-> ) ENGINE = InnoDB
-> PARTITION BY RANGE(id) (
-> PARTITION p0 VALUES LESS THAN(10000),
-> PARTITION p1 VALUES LESS THAN(20000),
-> PARTITION p2 VALUES LESS THAN(30000),
-> PARTITION p3 VALUES LESS THAN(40000),
-> PARTITION p4 VALUES LESS THAN(50000)
-> );
A RANGE partitioned table accepts only rows that match a partition.
LIST Partitioning
In the case of LIST Partitioning, you specify lists of values for each partition so that rows with matching column values are stored in the corresponding partition. For instance, assume that each of your orders is placed at one of several different stores organized into five districts, and you would like to store orders placed at each district in the same partition. Using this type of partitioning allows you to arbitrarily separate the stores. Suppose that you have 19 stores in these five districts, organized as shown in the figure below.
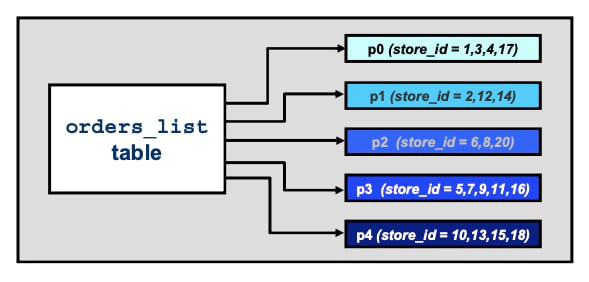
Use PARITION BY LIST to partitions rows that contain specified values. In this “store orders” example, partitions are specified for orders by store IDs, per district. You can create an orders_list table that assigns orders coming from stores in the same district to the same partition (as the diagram above shows) as follows:
mysql> CREATE TABLE orders_list (
-> id INT AUTO_INCREMENT, customer_surname VARCHAR(30), store_id INT,
-> salesperson_id INT, order_date DATE, note VARCHAR(500),
-> INDEX idx (id)) ENGINE = InnoDB
-> PARTITION BY LIST(store_id) (
-> PARTITION p0 VALUES IN (1, 3, 4, 17),
-> PARTITION p1 VALUES IN (2, 12, 14),
-> PARTITION p2 VALUES IN (6, 8, 20),
-> PARTITION p3 VALUES IN (5, 7, 9, 11, 16),
-> PARTITION p4 VALUES IN (10, 13, 15, 18)
-> );
A LIST partitioned table accepts only rows that match a partition.
HASH Partitioning
HASH is used primarily to ensure an even distribution of data among a predetermined number of partitions. This distribution is based on an expression that you supply when you create the table. Use the keyword PARTITIONS followed by the desired (integral) number of partitions.
PARTITION BY HASH ensures an even distribution of data among partitions. Unlike RANGE or LIST, HASH, HASH Partitioning does not require individual partition definition. In this “store orders” example, an integer is specified to partition the table into four equal partitions:
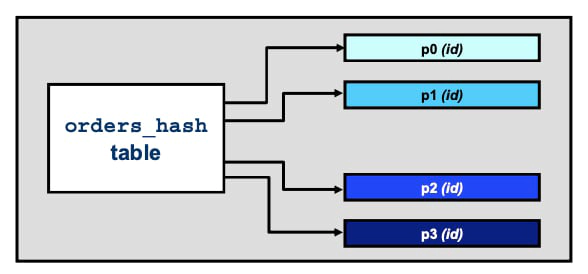
The following statement creates four partitions based on a hash of the id column:
mysql> CREATE TABLE orders_key (
-> id INT AUTO_INCREMENT, customer_surname VARCHAR(30), store_id INT,
-> salesperson_id INT, order_date DATE, note VARCHAR(500),
-> INDEX idx (id) ) ENGINE = InnoDB
-> PARTITION BY KEY(order_date) PARTITIONS 4;
KEY Partitioning
Instead of using a partitioning expression that returns an integer or NULL, the expression following [LINEAR] KEY consists simply of a list of zero or more column names, with multiple names being separated by commas.
PARTITION BY KEY is similar to HASH except that the MySQL server uses its own hashing expression. It does not require that the partition expression return an integer or NULL. In this “store orders” example, partitions are specified by date of order:
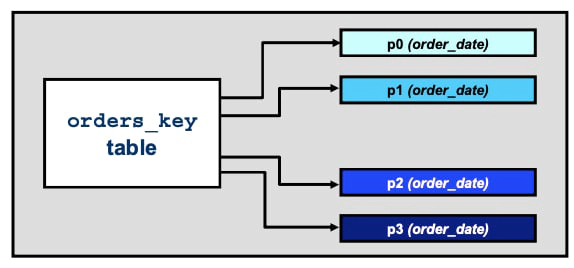
The example above creates the orders_key table, which partitions by the date of a placed order:
mysql> CREATE TABLE orders_key (
-> id INT AUTO_INCREMENT, customer_surname VARCHAR(30), store_id INT,
-> salesperson_id INT, order_date DATE, note VARCHAR(500),
-> INDEX idx (id) ) ENGINE = InnoDB
-> PARTITION BY KEY(order_date) PARTITIONS 4;
Subpartitioning
Subpartitioning (also known as composite partitioning) is the further division of each partition in a partitioned table. Subpartitions can use HASH, LINEAR HASH, KEY, or LINEAR KEY partitioning. For instance, you can create a new table (similar to the orders_range table) that takes the partitioning a step further with subpartitions.
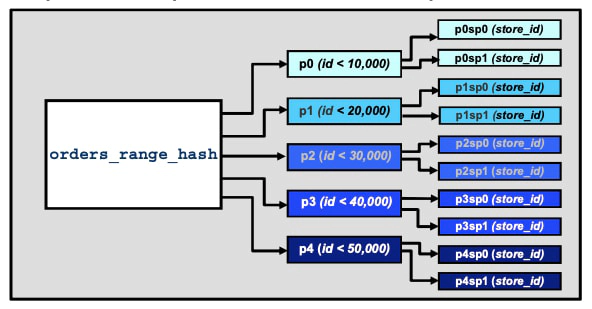
In this “store orders” database example, based on the orders_range table, you can further divide a table so that it splits each partition into two subpartitions:
mysql> CREATE TABLE orders_range_hash (
-> ...
-> ) ENGINE = InnoDB
-> PARTITION BY RANGE(id)
-> SUBPARTITION BY HASH(store_id)
-> SUBPARTITIONS 2 (
-> PARTITION p0 VALUES LESS THAN(10000),
-> PARTITION p1 VALUES LESS THAN(20000),
-> PARTITION p2 VALUES LESS THAN(30000),
-> PARTITION p3 VALUES LESS THAN(40000),
-> PARTITION p4 VALUES LESS THAN(50000)
-> );
The orders_range_hash table is partitioned by RANGE and subpartitioned by HASH. In other words, each of the RANGE partitions is divided into HASH (sub)partitions for a total of 5 * 2 = 10 subpartitions.
Obtaining Partition Information
MySQL provides several methods for determining the partition status of a table:
– View the partitioning clauses used in creating a partitioned table.
SHOW CREATE TABLE
– Determine whether a table is partitioned.
SHOW TABLE STATUS
– Query the INFORMATION_SCHEMA.PARTITIONS table.
INFORMATION_SCHEMA.PARTITIONS
– Show which partitions are used by a given SELECT statement.
EXPLAIN PARTITIONS SELECT
- Show what syntax is used to create a table, including the PARTITION BY clause:
mysql> SHOW CREATE TABLE orders_hash\G
******************** 1. row ********************
Table: orders_hash
Create Table: CREATE TABLE `orders_hash` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`customer_surname` varchar(30) DEFAULT NULL,
`store_id` int(11) DEFAULT NULL,
`salesperson_id` int(11) DEFAULT NULL,
`order_date` date DEFAULT NULL,
`note` varchar(500) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1
/*!50100 PARTITION BY HASH (id) PARTITIONS 4 */
- Determine whether a table is partitioned:
mysql> SHOW TABLE STATUS LIKE 'orders_hash'\G
******************** 1. row ********************
Name: orders_hash
Engine: InnoDB
...
Create_options: partitioned
Comment:
The SHOW TABLE STATUS statement output is the same as that for non-partitioned tables, except that the Create_options column contains the string partitioned. The Engine column contains the name of the storage engine used by all partitions of the table.
- The INFORMATION_SCHEMA.PARTITIONS table can be queried for partition details. To get a list of all database tables and their partitions:
mysql> SELECT TABLE_NAME,
-> GROUP_CONCAT(PARTITION_NAME)
-> FROM INFORMATION_SCHEMA.PARTITIONS
-> WHERE TABLE_SCHEMA='orders'
-> GROUP_BY TABLE_NAME;
+--------------+------------------------------+
| table_name | group_concat(partition_name) |
+--------------+------------------------------+
| orders_range | p0,p1,p2,p3,p4 |
| orders_hash | p0,p1,p2,p3 |
| orders_key | p0,p1,p2,p3 |
| orders_list | p0,p1,p2,p3,p4 |
...
To list the partition names with respective partitioning descriptions for a specific table:
mysql> SELECT PARTITION_NAME, PARTITION_DESCRIPTION
-> FROM INFORMATION_SCHEMA.PARTITIONS
-> WHERE TABLE_NAME='orders_list'
-> AND TABLE_SCHEMA='orders';
+----------------+-----------------------+
| PARTITION_NAME | PARTITION_DESCRIPTION |
+----------------+-----------------------+
| p0 | 1,3,4,17 |
| p1 | 2,12,14 |
| p2 | 6,8,20 |
| p3 | 5,7,9,11,16 |
| p4 | 10,13,15,18 |
+----------------+-----------------------+
- EXPLAIN PARTITIONS - Shows how MySQL is processing partitions. Tells which partitions are being accessed for a query and how they are used. It can be used only on tables containing row data:
EXPLAIN PARTITIONS SELECT * FROM orders_range\G
******************** 1. row ********************
id : 1
select_type : SIMPLE
table : orders_range
partitions : p0,p1,p2,p3,p4
type. : ALL
possible_keys : NULL
key : NULL
key_len : NULL
ref : NULL
rows : 21
Extra :
Altering a Partition
Databases are usually dynamic, requiring changes to existing partition settings. MySQL allows several types of partition alterations:
- Add
- Drop
- Merge
- Split
- Reorganize
- Redefine
Simple extensions to the ALTER TABLE statement are used to make these alterations. Although each partition alteration type is important to you as a DBA, most DBAs are more concerned with redefining and dropping partitions than the other types. Therefore, this post addresses only these two types.
Redefining the Partitioning Type
We can change a non-partitioned table into a partitioned table or completely redefine existing partitioning, including type. For example using ALTER TABLE with PARTITION BY, we change the partition type from RANGE to HASH:
ALTER TABLE orders_range
PARTITION BY HASH(id) PARTITIONS 4;
Exchanging Partitions
To exchange a table partition or subpartition with a table:
- Move any existing rows in the partition or subpartition to the non-partitioned table.
- Move any existing rows in the non-partitioned table to the table partition or subpartition.
The table to be exchanged must not be partitioned. It must have the same table structure as the partitioned table. Rows in the non-partitioned table prior to the exchange must lie within the range defined for the partition or subpartition.
ALTER TABLE orders_range
EXCHANGE PARTITION p0
WITH TABLE orders;
When exchanging a partition with a non-partitioned table, the table has the same limitations as a partition. For example, the table must not have a foreign key and must not contain a column that is a foreign key in another table. These and other limitations are covered in a later slide titled “Partitioning Limitations.”
Effects of exchanging partitions include:
- Exchanging a partition does not invoke triggers on either the partitioned table or the exchanged table.
- Any AUTO_INCREMENT columns in the exchanged table are reset.
Dropping Partitions
You can remove one or more partitions. This is allowed for RANGE or LIST tables. Use ALTER TABLE with DROP PARTITION to drop a partition. In this orders_range table example, all the order IDs of less than 10,000 have been filled, so the first partition is dropped:
ALTER TABLE orders_range DROP PARTITION p0;
The partition scheme is now changed:
+----------------+-----------------------+
| PARTITION_NAME | PARTITION_DESCRIPTION |
+----------------+-----------------------+
| p0 | 10000 |
| p1 | 20000 |
| p2 | 30000 |
| p3 | 40000 |
| p4 | 50000 |
+----------------+-----------------------+
Note that dropping a partition is not the same as removing the rows. Although it does have the effect of removing all the data within the partition, the primary intention for using DROP PARTITION is to remove the partition designation itself, and to no longer allow data to be funneled into that partition.
You can delete all rows from one or more partitions of a partitioned table using the ALTER TABLE … TRUNCATE PARTITION statement. When you execute this statement, it deletes rows without affecting the structure of the table. The partitions named in the TRUNCATE PARTITION clause do not have to be contiguous. DROP PARTITION and TRUNCATE PARTITION are similar to DROP and TRUNCATE TABLE in speed.
Issues with Using DROP PARTITION
The DROP privilege is required to use DROP PARTITION.When you drop a partition, you delete all the data that was in that partition, just as if you had run the equivalent DELETE statement. ALTER TABLE…DROP PARTITION does not return the number of rows that were dropped. If you need this information, use SELECT COUNT() or DELETE. DROP PARTITION changes the table definition. Partitions can be dropped in any order.
You can drop multiple partitions in a single statement by using the names of the partitions, separated by commas, in the DROP PARTITION clause. Rows inserted into the dropped partitions are handled according to the new partitions. For example:
ALTER TABLE orders_range DROP PARTITION p1, p3;
Dropping a LIST partition prohibits INSERT and UPDATE operations that would have matched that partition. Dropping a RANGE partition removes the partition and its data. New data from INSERT and UPDATE operations are stored in the next, greater, partition in the range. If there are no partitions with a range greater than that of the dropped partition, you cannot perform INSERT and UPDATE operations on data in the dropped partition’s range.
Removing Partitioning
To remove all partitioning from a table so that it returns to being a non-partitioned table, use an ALTER TABLE with REMOVE PARTITIONING. This does not delete any table data. For example, return the orders_range table to a non-partitioned state:
ALTER TABLE orders_range REMOVE PARTITIONING;
The orders_range table no longer contains partitions:
+---------------+----------------+-----------------------+
| TABLE_NAME | PARTITION_NAME | PARTITION_DESCRIPTION |
+---------------+----------------+-----------------------+
| orders_range | NULL | NULL |
+---------------+----------------+-----------------------+
REMOVE PARTITIONING does a full table copy, like a normal ALTER TABLE ALGORITHM=COPY. After the partitioning is removed, the table definition no longer includes the PARTITION BY portion. Also there are no longer any partitions listed if you attempt to query the partitions in the INFORMATION_SCHEMA.PARTITIONS table, as shown in the example in the slide.
Performance Effects of Altering a Partition
Depending on the number of partitions, creating partitioned tables is slightly slower than creating non-partitioned tables. Partitioning operation processing speed comparisons:
- DROP PARTITION is much faster than DELETE for large transactional tables.
- ADD PARTITION is fairly quick on RANGE and LIST tables.
- For ADD PARTITION on KEY or HASH tables, speed depends on the number of rows already stored. It takes longer to add new partitions when there is more data.
- COALESCE PARTITION, REORGANIZE PARTITION, and PARTITION BY can be slow when run on very large tables.
During such operations, the overhead of hardware I/O is much higher than that of the partitioning engine. ADD PARTITION on KEY/HASH redistributes all rows to the new number of partitions, effectively working as a full table copy. The same result occurs with **COALESCE PARTITION **and PARTITION BY. ADD/COALESCE PARTITION for LINEAR HASH/KEY partitions only splits/merges the affected number of partitions. REORGANIZE PARTITION depends on the size of the partitions to reorganize.
Partitioning: Storage Engine Features
Each PARTITION clause can include a [STORAGE] ENGINE option. This has no effect. Each partition uses the same storage engine as that used by the table as a whole. Partitioning applies to all data and indexes of a table. Note that you cannot partition only the data or only the indexes. Partitions are stored in their own files in the data directory by default. Use DATA DIRECTORY to specify an alternative partition location:
CREATE TABLE entries (id INT, entered DATE) PARTITION BY RANGE(YEAR(entered)) (
PARTITION p0 VALUES LESS THAN (2000) DATA DIRECTORY = '/data/p0',
PARTITION p1 VALUES LESS THAN MAXVALUE DATA DIRECTORY = '/data/p1' );
Partitioning is implemented as a storage engine. A partitioned table uses a combination of the partitioning storage engine and the backing storage engine (for example, InnoDB). Other storage engines can also use partitioning; however, the MERGE, CSV, and FEDERATED storage engines cannot use partitioning.
Partitioning and Locking
MySQL tables are locked as part of the server code. Locking is handled by the table storage engine during each statement. Each storage engine deals with locks differently. When you execute an ALTER…PARTITION operation on a table, it takes a write lock on the table. Reads from such tables are relatively unaffected; pending INSERT and UPDATE operations are performed as soon as the partitioning operation has completed.
When you execute an ALTER TABLE t [CMD] PARTITION type statement, it requires a write lock on the table during the copy phase, unless the command supports online operations with ALGORITHM=INPLACE. When the copy phase is done, it needs exclusive access to the table to change the table definition.
Partitioning Limitations
General: – The maximum number of partitions per table is 8192. – Spatial types are not supported. – Temporary tables cannot be partitioned. – It is not possible to partition log tables.
Foreign keys and indexes: – Foreign keys are not supported. – FULLTEXT indexes are not supported. – No global indexes: Each partition has its own indexes.
Subpartitioning is possible only: – When partitioning by RANGE and LIST – By LINEAR HASH or LINEAR KEY
Partition Expression Limitations
Expressions used for RANGE, LIST, and HASH partitions must evaluate as an integer. RANGE COLUMNS and LIST COLUMNS allow a wider range of data types. You cannot use TEXT or BLOB in partitioning expressions. UDFs, stored functions, variables, some operators (|, &, ^, <<, », ~), and some built-in functions are not allowed.
SQL modes should not be changed after table creation. Subqueries are not supported in partitioning expressions. All columns used in the partitioning expression must be part of all of the table’s unique indexes. The unique key that must reference the columns in the partitioning expression includes the table’s primary key, because it is by definition a unique key. This is because the indexes are partitioned together with the data. To keep the “uniqueness,” two rows with the same unique key must go to the same partition; otherwise, they violate the unique key restriction.